Experience the Power of Crawl4ai – Start Your Free Trial Today!
Unlock valuable insights and streamline your projects with Crawl4ai’s intuitive features.
Click here to start your free trial.

Introduction to Crawl4ai
Many developers face challenges when it comes to efficiently extracting data from various websites. Are you struggling with slow performance, complex setup processes, or compatibility issues with different web browsers? If so, you may find that the open-source Python library Crawl4AI provides solutions to these problems. Designed with efficiency in mind for web crawling and data extraction, Crawl4AI aims to simplify the process for developers and researchers working with AI applications and large language models (LLMs).
Key Features and Benefits of Crawl4ai
- Free and open-source for easy access and community support.
- Fast performance that can often surpass paid services.
- LLM-friendly output formats such as JSON, cleaned HTML, and markdown.
- Multi-browser support for crawling (Chromium, Firefox, WebKit).
- Concurrent URL crawling that enhances efficiency.
- Media extraction, including images, audio, video, and metadata.
- Custom hooks for authentication and page modifications.
- User-agent and proxy customization for flexibility in crawling.
- Advanced extraction strategies and chunking methods.
- Improved handling of delayed content with lazy-loading detection.
5 Tips to Maximize Your Use of Crawl4ai
- Utilize Magic Mode for enhanced data extraction capabilities.
- Familiarize yourself with session management for handling complex crawls efficiently.
- Leverage hooks for authentication to maintain secure connections while crawling.
- Experiment with various proxy configurations to optimize your output and access controls.
- Make use of CSS-based extraction techniques to refine your data collection process.
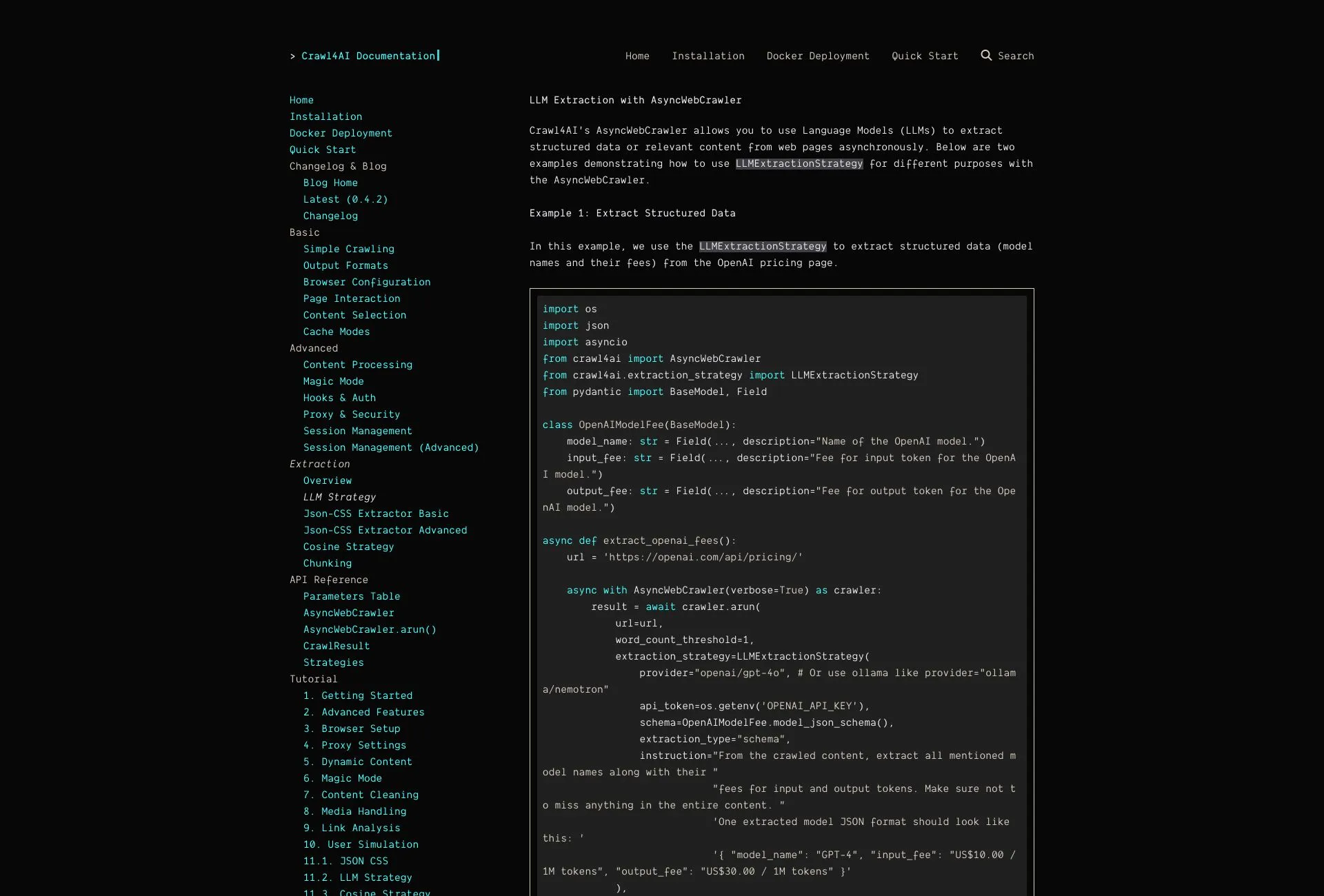
How Crawl4ai Works
The core functionality of Crawl4AI is centered around its ability to manage asynchronous web crawling, making it significantly faster and more efficient than traditional methods. It employs a multi-browser crawling approach to navigate various website structures and layouts, ensuring compatibility across platforms. The library allows for concurrent requests, enabling users to scrape multiple URLs simultaneously. Additionally, Crawl4AI offers customizable output formats and hooks that enhance user control over the crawling process.
Real-World Applications of Crawl4ai
Crawl4AI is particularly effective in scenarios across diverse industries such as:
- Market Research: Collecting product reviews and trends from multiple e-commerce sites.
- Academic Research: Gathering data and publications from scholarly articles and websites.
- Content Aggregation: Compiling news articles, blog posts, and other media.
- Social Media Analytics: Extracting user-generated content and sentiment analysis.
Challenges Solved by Crawl4ai
Crawl4AI addresses several key challenges faced during web scraping, including:
- Performance Issues: Speeding up the crawling process with asynchronous requests.
- Complex Page Structures: Handling dynamic content and lazy-loading elements.
- Data Format Compatibility: Providing outputs in various formats tailored for LLMs.
- Authentication Barriers: Facilitating smooth access to secured sites with custom hooks.
Ideal Users of Crawl4ai
Crawl4AI is ideally suited for:
- Developers: Building applications that require web data.
- Data Scientists: Analyzing online datasets for research and analytics.
- Researchers: Collecting academic papers and articles.
- Marketers: Monitoring online competition and industry trends.
What Sets Crawl4ai Apart
Crawl4AI distinguishes itself from competitors through:
- Open-source nature: Grants users flexibility and customization options.
- Asynchronous architecture: Enables significantly faster data extraction.
- Support for diverse media: Extracts a wide variety of data types seamlessly.
Improving Work-Life Balance with Crawl4ai
By streamlining the data extraction process, Crawl4AI can dramatically enhance your professional efficiency. This allows you to allocate time saved from manual data collection to strategic thinking, innovation, and overall work-life balance. With user-friendly features and robust performance, Crawl4AI empowers you to focus on delivering quality results rather than getting bogged down by tedious crawling tasks.
Crawl4ai: Advanced Web Data Extraction
Speed
Asynchronous crawling with concurrent URL processing for maximum performance and efficiency.
Format
LLM-friendly output in JSON, HTML, and markdown formats with advanced extraction strategies.
Browser
Multi-browser support including Chromium, Firefox, and WebKit for comprehensive compatibility.
Custom
Flexible hooks for authentication, proxy configuration, and page modifications to meet specific needs.
PopularAiTools.ai
