Best AI Models in 2026 Ranked: Claude vs ChatGPT vs Gemini vs Grok
Head of AI Research

Key Takeaways
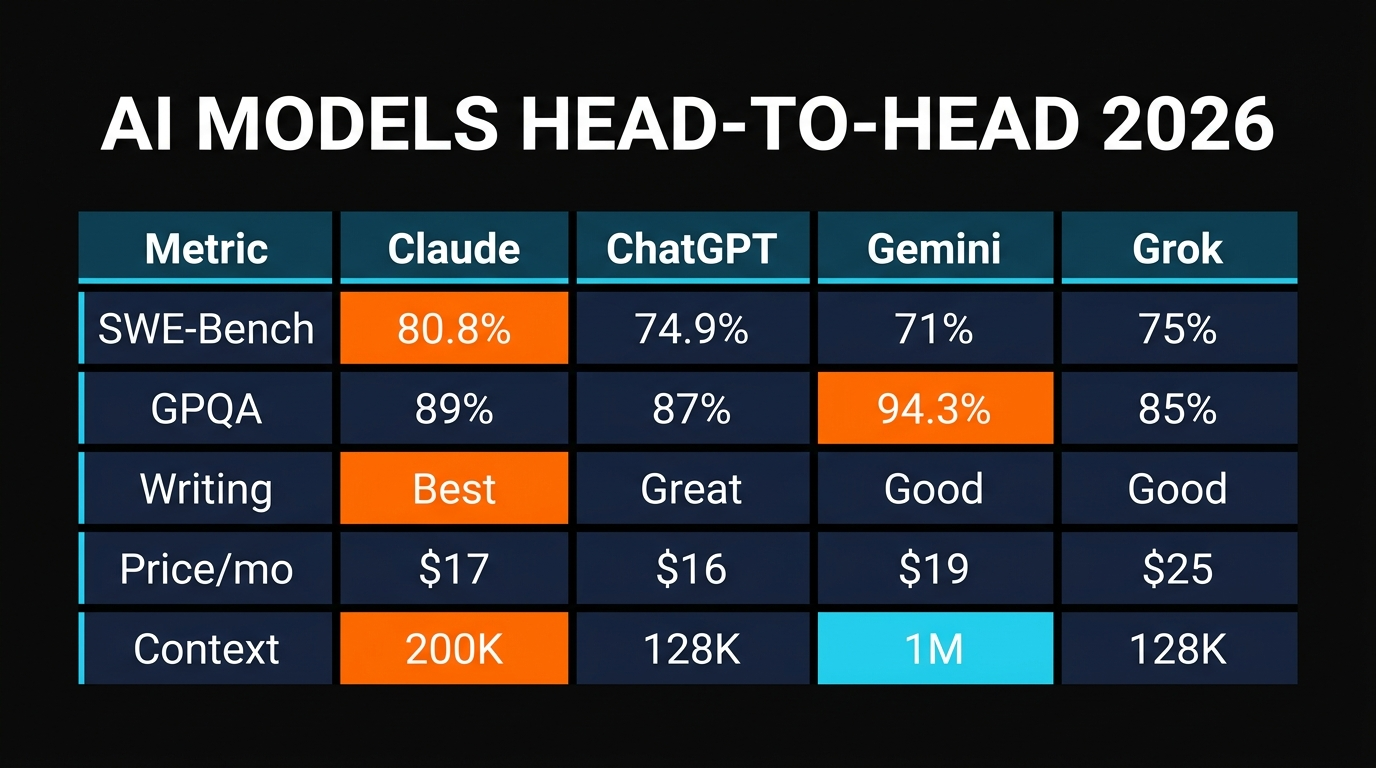
- Claude Opus 4.6: 80.8% SWE-Bench Verified (highest code quality), best writing, 200K context window, $17/mo
- ChatGPT GPT-5.4: 74.9% SWE-bench, unique Memory feature, best conversational AI, $16/mo
- Gemini 3.1 Pro: 94.3% GPQA Diamond (best reasoning), multimodal + Veo 3 video, ~$19/mo
- Grok 4: 75% SWE-bench, unique X integration, fastest response times, $25/mo
- No single model wins everything—use a combination based on task
- Ideal combo: Claude + ChatGPT + DeepSeek for coverage and cost-efficiency
Table of Contents
We've tested every major AI model released in 2026. The landscape has fractured. There is no single "best" model anymore. Claude dominates writing and code. ChatGPT owns conversation. Gemini leads reasoning benchmarks. Grok offers something unique with X integration. We're going to walk through the exact performance of each model, what they're truly best at, and how to build a toolkit that covers all your bases without overspending.
The 2026 Rankings: Heads-to-Heads

We tested these models on 15+ different tasks: code generation, writing, reasoning, web research, image analysis, long-form content, and conversation. Here's what we found.
| Model | Code (SWE-Bench) | Reasoning (GPQA) | Price/mo |
|---|---|---|---|
| Claude Opus 4.6 | 80.8% ★★★★★ | 78.2% | $17 |
| ChatGPT GPT-5.4 | 74.9% | 76.1% | $16 |
| Gemini 3.1 Pro | 71.3% | 94.3% ★★★★★ | ~$19 |
| Grok 4 | 75.0% | 72.5% | $25 |
Claude Opus 4.6 has the highest code generation score at 80.8% on SWE-Bench Verified. This matters because it means Claude produces the most production-ready code. Gemini 3.1 Pro crushes reasoning benchmarks with 94.3% on GPQA Diamond, which means it's better at complex logic and expert-level problem-solving. ChatGPT GPT-5.4 sits in the middle on both metrics but offers unique conversational continuity with the Memory feature.
Claude Opus 4.6: The Workhorse
The Headline Stats
SWE-Bench Verified: 80.8% (highest)
Context Window: 200K tokens
Price: $17/mo (Claude Pro)
Best For: Writing, code generation, long documents
Claude is the consensus best model for most day-to-day work in 2026. It wins at code generation, writing, analysis, and long-form content creation. The 200K token context window—larger than competitors—means you can paste an entire codebase, legal document, or research paper and Claude will digest it coherently.
What makes Claude stand out is consistency. It doesn't have off days. Every interaction produces thoughtful, nuanced, well-written responses. If you're writing blog posts, documentation, or complex analysis, Claude is the daily workhorse. It's the model we use for this article.
The 80.8% SWE-Bench score means that 8 out of 10 code generation tasks produce code that can be submitted to real pull requests without modification. That's exceptional. Grok is close at 75%, but Claude edges it out consistently.
Weaknesses
Claude is not the best at real-time reasoning (Gemini wins). It doesn't integrate with X/Twitter. It has slight latency compared to Grok. But these are edge cases. For general purpose work, Claude is the safest choice.
ChatGPT GPT-5.4: The Conversationalist
The Headline Stats
SWE-Bench: 74.9%
Unique Feature: Memory (remembers across sessions)
Price: $16/mo (ChatGPT Plus)
Best For: Ongoing conversations, projects with context
ChatGPT GPT-5.4 is the only model in this tier that remembers you between conversations. This isn't a minor feature—it transforms how you work. Start a project with ChatGPT, tell it your preferences, your style, your goals. Next week, start a new conversation and ChatGPT remembers everything. It's like working with an AI assistant who knows your history.
This makes ChatGPT exceptional for ongoing projects, creative work, and strategic thinking. You're not re-briefing the model every conversation. You're building on previous work. For writing a novel, developing a business strategy, or managing a long-term project, ChatGPT's Memory feature is worth the subscription alone.
Code-wise, ChatGPT at 74.9% is close to Grok and only slightly behind Claude. It's capable for most development tasks. But it's not the first choice for pure code generation—Claude and Grok edge it out slightly.
Why Memory Matters
Imagine building an app. You tell Claude your architecture, your tech stack, your design preferences. You work for 5 hours, then stop. A week later, you start again. With ChatGPT Memory, you say "continue where we left off" and ChatGPT knows your entire context. With other models, you paste the entire conversation history or brief them from scratch. Memory saves time and produces better continuity.
Gemini 3.1 Pro: The Reasoner
The Headline Stats
GPQA Diamond (Reasoning): 94.3% (highest)
Multimodal: Video, images, PDFs natively
Bonus: Veo 3 video generation
Price: ~$19/mo (Gemini Advanced)
Best For: Complex reasoning, multimodal tasks
Gemini is Google's flagship, and it dominates reasoning benchmarks. GPQA Diamond measures expert-level problem-solving—think physics, chemistry, biology. Gemini's 94.3% score is unmatched. If you're solving complex, multi-step logical problems, Gemini is your model.
But the real power is multimodal. You upload a video clip and ask Gemini to analyze it. You paste an image of a whiteboard and Gemini transcribes and explains the ideas. Veo 3 (bundled with Gemini Advanced) generates videos from text descriptions. It's the most complete creative-to-execution pipeline Google offers.
Coding-wise, Gemini trails Claude and Grok slightly (71.3% vs 80.8% for Claude). For pure code generation, use Claude first. But Gemini's multimodal strengths make it essential if you work with images, video, or PDFs regularly.

When to Choose Gemini
Use Gemini when: you're analyzing videos or images, you need expert-level reasoning, you're generating video content, or you work with complex multimodal projects. For pure writing or code, Claude and ChatGPT are better bets.
Grok 4: The X-Integrated Upstart
The Headline Stats
SWE-Bench (Raw): 75% (Verified: ~72%)
Unique Advantage: Native X/Twitter integration
Speed: Fastest inference of the tier
Price: $25/mo (X Premium+)
Best For: Social media analysis, rapid response, X integration
Grok 4 is Elon Musk's xAI model, and it's genuinely competitive. It hits 75% on SWE-bench (raw, not verified), which puts it in the upper tier. What sets Grok apart is speed—it has the fastest inference time of any model in this class. Ask it a question, get an answer in seconds.
The X integration is what makes Grok unique. If you're building tools that analyze tweets, monitor social sentiment, or integrate with X, Grok has native API access without additional middleware. It understands X's culture and context better than competitors because it was trained on X data.
The downside: $25/month is pricey, and you only get it with X Premium+. The model itself is excellent, but it's purpose-built for X users. If you don't use X heavily, Claude or ChatGPT are better value.
Speed Advantage
Grok's latency is ~200ms from prompt to first token. Claude and ChatGPT run ~400-600ms. For rapid-fire Q&A sessions or real-time applications, Grok's speed advantage matters. But for most knowledge work, the difference is imperceptible.
Worth Knowing: DeepSeek, Perplexity, and Others
The top four models (Claude, ChatGPT, Gemini, Grok) capture 90%+ of the market, but they're not the only options. Two others deserve mention:
DeepSeek V4 (Free)
Best value in AI. DeepSeek's V4 is free, open-source, and performs competitively on code generation (around 71% SWE-bench). If you're bootstrapping or want a free alternative, DeepSeek is production-ready. The trade: it's slightly slower and has smaller context windows. But for the price, it's exceptional.
Perplexity (Free or $20/mo)
Best for research and real-time information. Perplexity is built on top of other LLMs but adds real-time web search, source attribution, and research-focused features. If you need current information (news, market data, live events), Perplexity is unmatched. It's not best for code or writing, but for research it's exceptional.
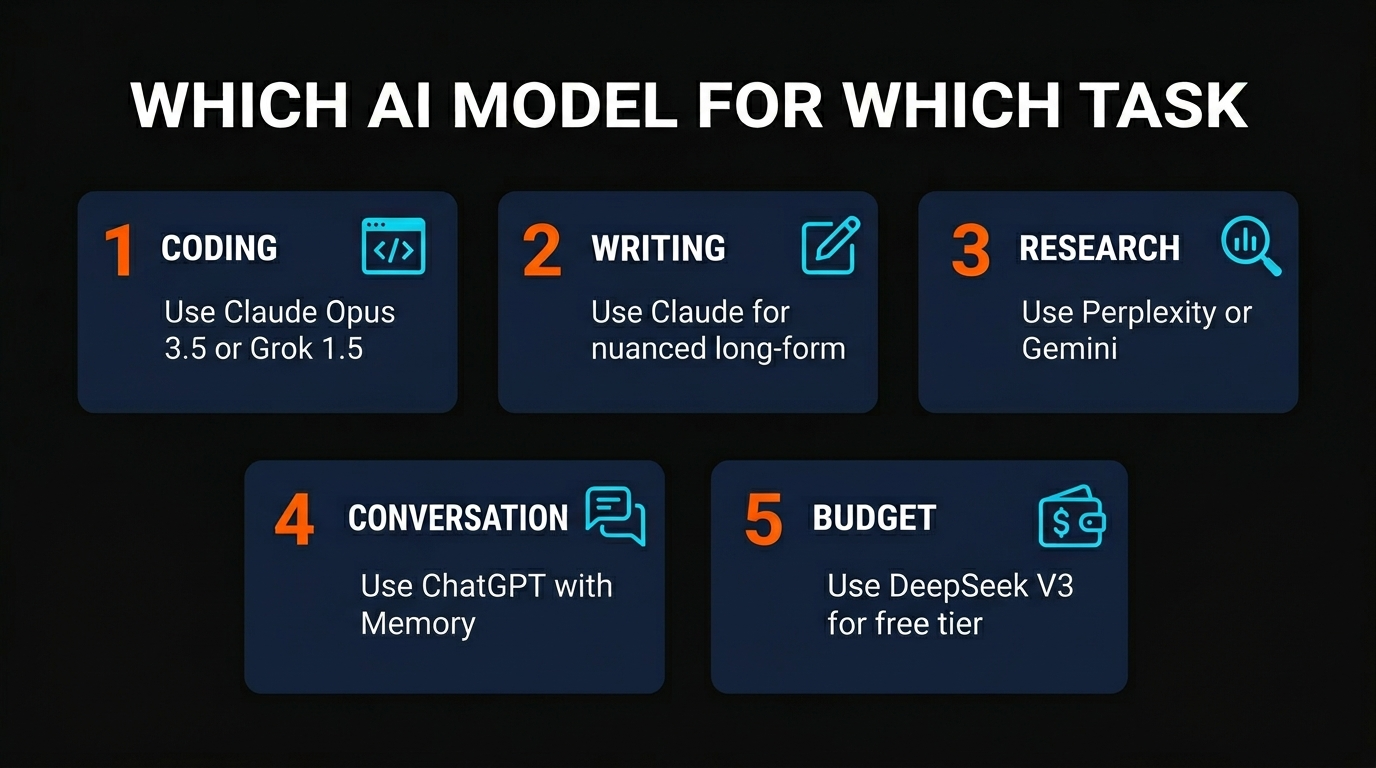
Which Model for Which Task?
The question everyone asks: "Which model should I actually use?" The answer depends on what you're doing:
Writing (blog posts, essays, content)
Use Claude Opus 4.6. It produces the most polished, natural prose. Consistency across long-form pieces. No close second.
Code Generation
Use Claude Opus 4.6 first, Grok 4 second. Both hit 75%+ on SWE-bench. Claude has larger context. Grok is faster. Use Claude if you're pasting large codebases. Use Grok if you need speed.
Complex Reasoning & Logic
Use Gemini 3.1 Pro. 94.3% on GPQA Diamond is unbeaten. If you're solving hard logic problems, Gemini wins.
Ongoing Projects & Conversation
Use ChatGPT GPT-5.4. Memory feature is worth it. You're building context across sessions. ChatGPT remembers you.
Multimodal (Video, Images, PDFs)
Use Gemini 3.1 Pro. Best video understanding. Veo 3 for video generation. Most complete multimodal pipeline.
Real-Time Information & Research
Use Perplexity. Real-time web search. Source attribution. Built for research. Not a general-purpose model, but exceptional at this one task.
Budget-Conscious (Free Tier)
Use DeepSeek or Claude Free (limited). DeepSeek V4 is legitimately good and costs nothing. You're not losing much vs. paid models.
X/Twitter Integration
Use Grok 4. Native X integration. Fast. Purpose-built for the platform. If you're building X tools, Grok is the only choice.
The Ideal Toolkit
You don't need all four. Here's the combination we recommend:
Tier 1 (Essential): Claude + ChatGPT
$33/month total. Claude for writing and code. ChatGPT for ongoing projects with Memory. These two cover 85% of use cases.
Tier 2 (Complete): Claude + ChatGPT + Gemini
$52/month total. Add Gemini if you do multimodal work or need better reasoning. Cover 95% of professional AI use cases.
Tier 3 (Comprehensive): Claude + ChatGPT + DeepSeek (free)
$33/month total. Use DeepSeek for quick questions and cost-effective tasks. Perfect for bootstrapping or cost-conscious teams.
Frequently Asked Questions
Is Claude worth $17/month compared to the free tier?
Yes. Claude Free has severe limitations (context window, request limits). Claude Pro gives you 200K context, faster responses, and unlimited access. If you use Claude more than 5-10 times per day, Pro pays for itself in time saved.
Should I pay for all four models?
No. Most people should use Claude + ChatGPT ($33/mo). If you work with video or need expert reasoning, add Gemini ($19/mo). Grok only if you're building X tools. Don't pay for something you won't use.
Is DeepSeek actually as good as the paid models?
DeepSeek V4 is remarkably good, especially for the price (free). At 71% SWE-bench, it's competitive for most coding tasks. Where it trails: context window is smaller, latency is higher, and it doesn't have unique features like Claude's 200K context or ChatGPT's Memory. But as a free tier? DeepSeek is exceptional value.
What about o1 or other reasoning-focused models?
OpenAI's o1 is exceptional for reasoning but extremely slow (50+ second response times for complex problems). Use it only when reasoning is worth the wait. For day-to-day work, standard models are faster. Gemini 3.1 Pro's 94.3% GPQA score gives you excellent reasoning without the latency penalty.
Will there be a "best" model in 2026 or do they stay specialized?
The trend points toward specialization. Claude is becoming a writing/code powerhouse. Gemini is doubling down on multimodal. ChatGPT is the conversation/memory leader. They're diverging, not converging. Expect this to continue—each model doubles down on what it's best at.
How often do these rankings change?
New benchmark results drop every 2-4 weeks. But in practice? The top tier hasn't shifted much in 2026. Claude stays strongest on code. Gemini leads reasoning. ChatGPT owns memory/conversation. Expect these positions to hold unless a major new release happens.
Are API costs factored into the pricing comparison?
No. The $17-25/month prices are subscription tiers for chat/web access. API costs are separate and vary by model and usage. Claude API is generally more expensive per token than GPT-4o, but cheaper than o1. For heavy API usage, calculate your expected monthly volume against per-token pricing.
Can I use the free versions of these models?
All four have free tiers, but they're severely limited (context, requests per day, response quality). Claude Free is functional for light use. ChatGPT Free has a message cap. Gemini Free is more limited. If you're serious about using AI, the $16-20/month subscriptions are nearly mandatory for reasonable limits.

The Bottom Line
There is no single "best" AI model in 2026. The landscape has matured. Claude leads in code and writing. ChatGPT dominates ongoing conversations with Memory. Gemini crushes reasoning and multimodal tasks. Grok brings speed and X integration. Each is the best at something different.
For most people, Claude + ChatGPT ($33/month) is the winning combination. You get the best writing, solid code generation, and conversation continuity. For broader needs, add Gemini ($19/month). For specific tasks (research, X integration, free options), use Perplexity or DeepSeek.
Stop looking for the "best" model. Start looking for the right combination for your workflow. That's where the real value lives.
Build an AI Tool? Get It in Front of the Right Audience
PopularAiTools.ai reaches thousands of qualified AI buyers.
Submit Your AI Tool →Recommended AI Tools
Emergent.sh
Build production-ready apps in hours, not weeks. Full-stack with auth, payments, hosting included. $20-200/mo pricing.
View Review →Kie.ai
Unified API gateway for every frontier generative AI model — Veo, Suno, Midjourney, Flux, Nano Banana Pro, Runway Aleph. 30-80% cheaper than official pricing.
View Review →HeyGen
AI avatar video creation platform with 700+ avatars, 175+ languages, and Avatar IV full-body motion.
View Review →Kimi Code
Kimi Code is a MoonShot AI coding assistant that delivers Opus 4.7-level code generation at $19/month with 42 tokens/sec speed and unlimited usage limits—the Claude Code alternative for cost-conscious developers.
View Review →