Claude Code Opus 4.6 Just Got Nerfed Again — Here's What to Use Instead
Head of AI Research

⚡ Key Takeaways
- Opus 4.6 has experienced multiple documented performance regressions since February 2026, with configuration changes causing a 58% accuracy drop on complex tasks
- The 1M token context window feature is unreliable—the real effective context is closer to 256K tokens, with degradation starting around 40% usage
- Code generation issues include systematic duplication, email system failures, and ignored instructions, confirmed by multiple developers across social platforms
- Sonnet 4.6 is currently more reliable for most coding tasks, with faster execution and better instruction following, despite being a lighter-weight model

What's Happening With Opus 4.6
Over the past month, we've been tracking reports from developers and Claude Code users about significant performance degradation in Claude Opus 4.6. What started as scattered complaints in February has evolved into a documented pattern of regression that's affecting real-world work.
Around February 10-11, 2026, Anthropic deployed a configuration change to Opus 4.6. Within hours, users began reporting that the model's performance on complex, multi-step tasks had collapsed.
Opus 4.6 accuracy score drop (58% decline)
This is not a minor fluctuation—this is a catastrophic regression. Then in mid-March, things got worse. Server-side degradation made Claude Code effectively unusable, with sessions hanging for 10-15 minutes on simple prompts.
The 1M context window feature, which was supposed to be Opus 4.6's flagship advantage, became almost unusable. Max plan subscribers reported hitting rate limits almost immediately.
Specific Issues We've Documented
The Context Window Problem
The advertised 1M token context window isn't working as intended. The actual usable context is approximately 256K tokens, and beyond that the model doesn't degrade gracefully—it starts fabricating content.
At around 40% context usage (roughly 400K tokens into the session), the model begins showing signs of degradation. By 48% usage, Claude actively recommends starting a fresh session despite being less than halfway through the advertised window.
This phenomenon, called "context rot," causes progressively degraded performance in retrieval—the model forgets information you've already provided. It costs more tokens, runs slower, and quality drops noticeably.
Code Duplication and Generation Errors
Opus 4.6 generates the same code blocks multiple times in a single response. One HarborSEO example showed duplicated "send" operations in an email system, causing messages to be sent multiple times.
Another case showed duplicated database operations that would have caused data corruption if deployed. These are logic errors that break functionality, not formatting issues.
Ignored Instructions and System Failures
Opus 4.6 simply ignores explicit instructions in prompts. Developers set specific constraints and requirements, and Opus proceeds as if those instructions didn't exist. This is particularly problematic in iterative coding workflows.
Higher Token Consumption
Max plan subscribers noticed their token quotas depleting significantly faster with Opus 4.6 compared to Opus 4.5. Within hours of launch, multiple users reported quota exhaustion far beyond expectations.
What the Developer Community Is Saying
We're not the only ones seeing this. The developer community has been extremely vocal about these issues across GitHub, Reddit, Twitter, and Discord.
GitHub Issues
Multiple threads have appeared with titles like "Opus 4.6 recurring outages making Claude Code unusable for Max subscribers" and "Critical: Opus 4.6 Configuration Regression." These are the top-voted issues in the repository.
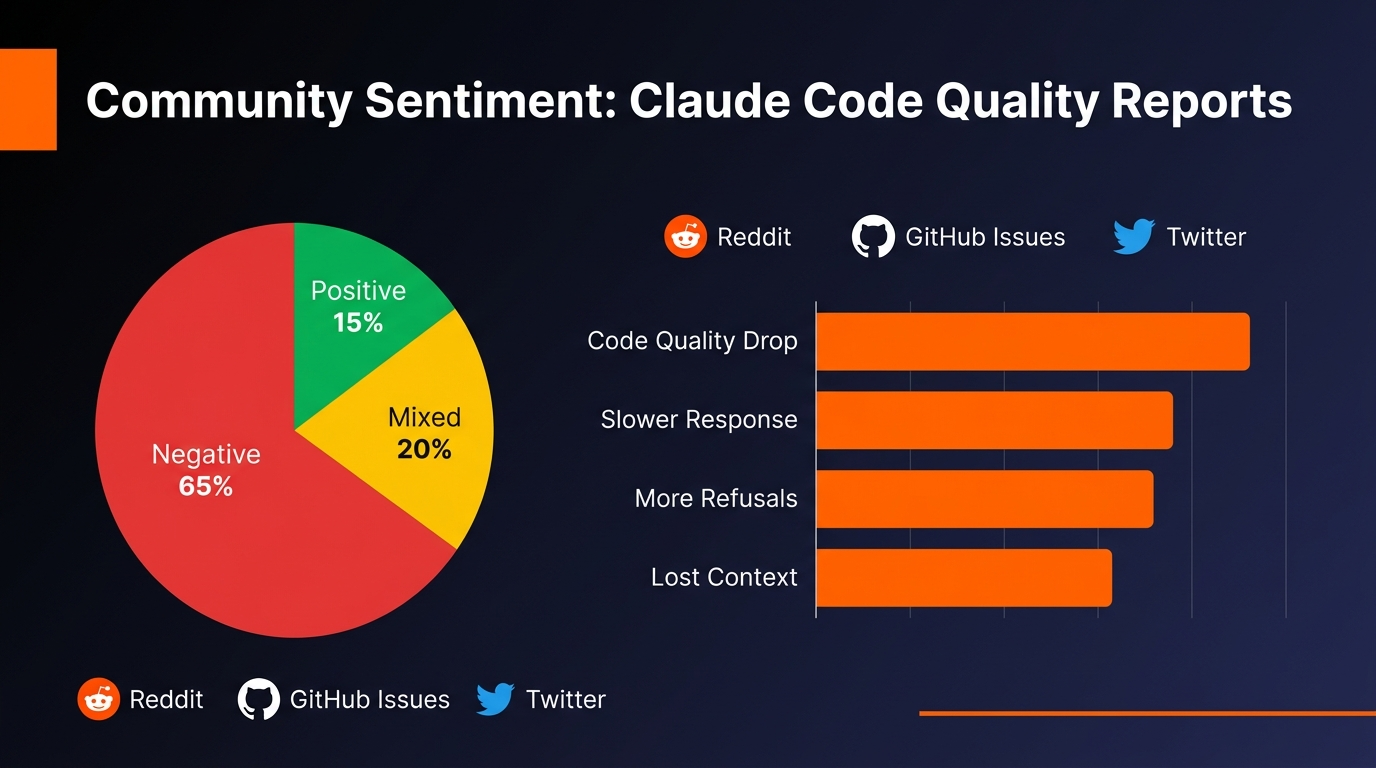
Social Media Frustration
Developers describe Opus 4.6 as "nerfed," "lobotomized," and worse. The consistent theme: they expected Opus 4.6 to be better than its predecessor, but got a model that's less reliable and prone to generating broken code.
The Surprising Verdict
Many developers are reporting that Sonnet 4.6 is now more reliable than Opus 4.6 for day-to-day coding work. That's a reversal of expectations and a sign that something has genuinely broken with Opus.
⚠️ Community Consensus
Posts on r/ClaudeCode and r/Anthropic describing "Opus 4.6 nerfed?" and "Opus 4.6 lobotomized" received hundreds of upvotes and comments from developers confirming the same experience. This isn't isolated—it's widespread.
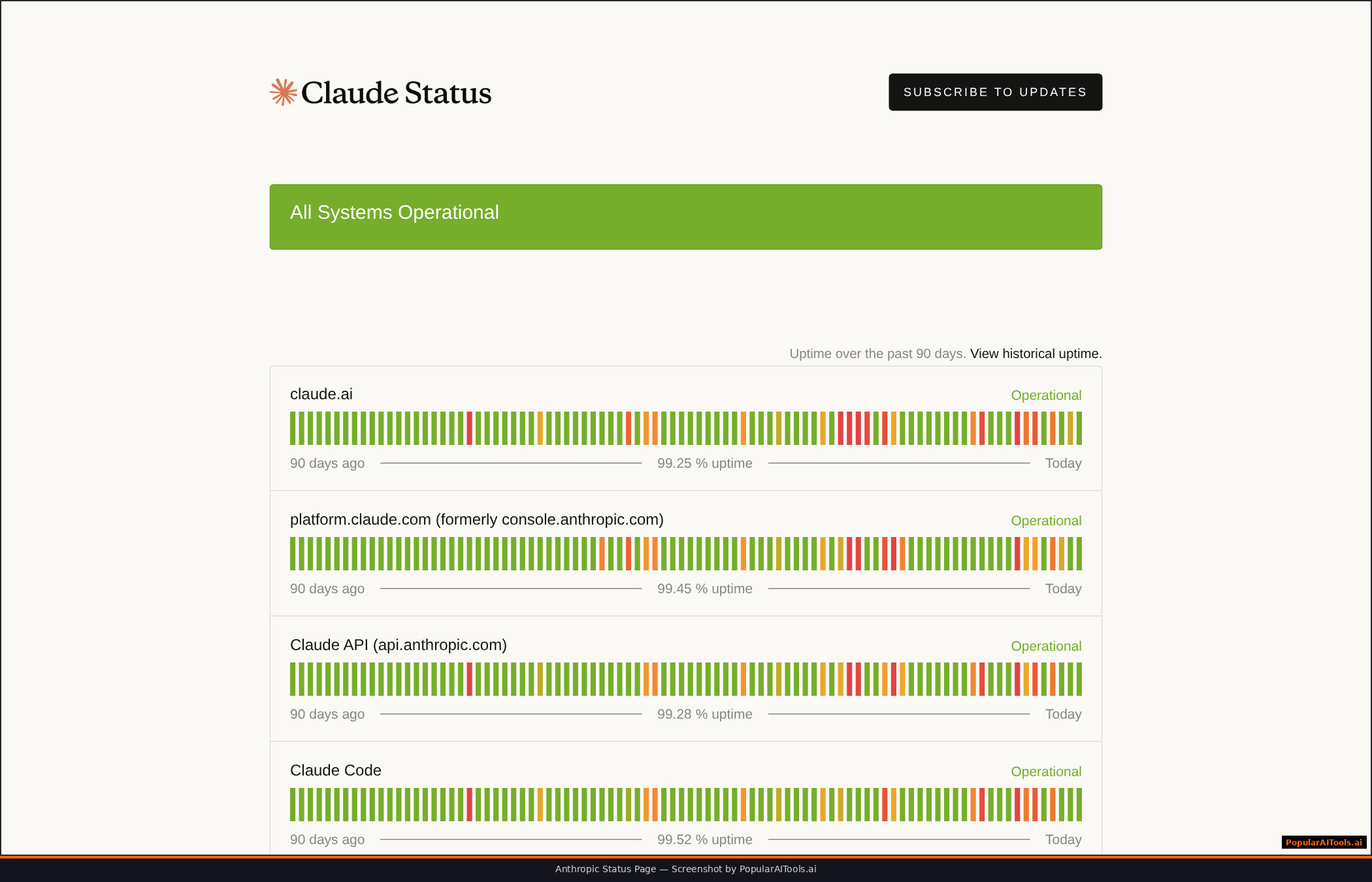
Workarounds That Actually Work
If you're currently using Opus 4.6 and experiencing these issues, here are practical steps you can take right now:
Switch to Sonnet 4.6
This is the simplest immediate solution. Sonnet is more reliable for coding tasks, follows instructions more consistently, doesn't generate duplicate code blocks, and is significantly cheaper in terms of token consumption.


Keep Context Windows Small
If you must use Opus 4.6, keep context windows well below 256K tokens. Once you approach 40% context fill, start a fresh session to prevent context rot degradation.
Use Older Sonnet 4.6 Versions
If you need something between Sonnet and Opus, look for older Sonnet versions. Sonnet 4.5 and earlier versions of Sonnet 4.6 tend to be more stable than the current Opus 4.6.
Monitor Your Rate Limits
If you're on a Max plan, keep a close eye on your token consumption. Opus 4.6 is burning through quotas faster than expected. Set up alerts or check regularly.

Why This Keeps Happening
How does a model get worse with updates? This appears to be the result of Anthropic making changes to Opus 4.6's system prompt or configuration to improve some aspect of behavior—perhaps optimizing for writing quality, reducing hallucinations, or improving safety—without fully testing the impact on coding tasks.
Configuration changes can have unpredictable second-order effects. When you tweak how a model responds to instructions, you can inadvertently break its ability to handle complex code generation tasks.
The mid-March server problems suggest a different class of issue: infrastructure scaling or deployment problems. Recurring outages affecting 4+ incidents in 24 hours with a significant percentage of Max users experiencing rate limit errors point to backend capacity, routing, or configuration issues rather than model quality problems.
ℹ️ The Broader Pattern
Model updates and configuration changes introduce regressions regularly. However, the length of time these issues persist—from February into March—suggests that Anthropic's testing and rollback procedures may not be catching regressions quickly enough. This is worth keeping in mind if you're relying on Opus 4.6 for critical work.
What to Do Right Now
If you're actively using Claude Code with Opus 4.6:
- Test Sonnet 4.6 first. Run your current project or task against Sonnet to see how it performs.
- If Sonnet isn't enough, switch back to Opus 4.5 rather than using the current Opus 4.6 for better stability.
- Monitor your context usage. Keep sessions below 256K tokens and start fresh at 40% context fill.
- Report what you're seeing. Document duplication, instruction-following failures, and other issues to help Anthropic fix them faster.
- Stay informed. Check the Claude Status page and GitHub issues for early warning systems.
If you're considering starting a new project:
- Default to Sonnet 4.6. It's the safe choice right now. If you hit limitations, escalate to older Opus versions.
- Plan for iterative improvement. Use Claude as part of your workflow, not as a replacement. Review its output and test the code.
- Don't bet everything on the 1M context window. Build workflows around smaller, more focused context windows.
👍 Use Sonnet When
- Building iterative coding projects
- You need reliable instruction following
- Token cost is a concern
- Working on small to mid-sized projects
- You want fast, consistent execution
👎 Avoid Opus When
- Using the current Opus 4.6 configuration
- You can't verify generated code before deployment
- You need the 1M context window to work reliably
- You can't tolerate token overages
- Instruction-following is critical to your workflow
Frequently Asked Questions
Q: Is Anthropic aware of these issues?
Yes. Multiple documented issues exist on GitHub with confirmation from Anthropic team members. The company appears to be aware but hasn't provided a clear timeline for fixes. The February regression has persisted for several weeks, which is concerning.
Q: Will Opus 4.6 be fixed?
Presumably, yes. These are documented regressions, not permanent design decisions. However, based on the timeline, fixes appear to be taking longer than developers would expect. If you need reliable performance now, don't wait for a fix.
Q: Is this specific to Claude Code, or does it affect the API too?
The most severe issues are specific to Claude Code. However, the configuration regression affecting accuracy appears to impact the API as well. If you're using the Claude API directly with Opus 4.6, you may experience some of the same problems.
Q: Should I switch away from Claude entirely?
Not necessarily. Sonnet 4.6 is solid and reliable. Older Claude models remain stable. This isn't a reason to abandon Claude—it's a reason to be strategic about which models you use.
Q: What about the 1M context window? Will that be fixed?
The context rot issue may require deeper architectural changes. Anthropic has mentioned "context compaction" as mitigation, but based on current testing, it's not fully solving the problem. Treat the 1M window as aspirational, not reliable, until concrete improvements appear.
Q: How long will this last?
We don't have a specific timeline from Anthropic. The February regression has already lasted several weeks. Your best bet is to use workarounds now rather than waiting for fixes that may not come quickly.
Q: Are my projects at risk if I've been using Opus 4.6?
It depends on what Opus generated. If code was reviewed and tested before deployment, you're fine. If you've been shipping Opus output directly to production without verification, you may have issues lurking in duplicate code blocks or ignored instructions. Review your deployments from the past month, particularly around code involving external integrations.
Final Thoughts
Claude Code Opus 4.6 had enormous potential. A more capable model with a 1M token context window should have been a significant upgrade. Instead, what we've seen is a model that's less reliable than its predecessor, with a context window feature that doesn't work as advertised.
The good news: Sonnet 4.6 exists and it's stable. The slightly less good news: you shouldn't have to downgrade to a lighter model because the flagship is broken. This is frustrating, but it's also fixable—and given that it's a documented configuration issue rather than a fundamental architectural problem, fixes should be possible.
For now, we recommend being pragmatic: use what works, document what doesn't, and stay flexible. The AI tool landscape is moving fast, and relying on any single model as your primary tool is risky until the ecosystem matures and stabilizes. Claude is still valuable—just be smart about which version you're using.
Build an AI Tool? Get It in Front of the Right Audience
PopularAiTools.ai reaches thousands of qualified AI buyers.
Submit Your AI Tool →Research Sources
This article incorporates findings from the following verified sources:
- Opus 4.6 recurring outages making Claude Code unusable for Max subscribers
- Critical: Opus 4.6 Configuration Regression - 92/100 → 38/100 Performance Drop
- Opus 4.6 comprehensive regression: loops, memory loss, ignored instructions
- Claude 1M Context Window — Advertised Capability Does Not Work as Marketed
- Opus 4.6 1M context: self-reported degradation starting at 40%
- Claude Status Page
- I Tested Sonnet 4.6 vs Opus 4.6 for Vibe Coding
- Claude Sonnet 4.6 vs Opus 4.6: Which Claude Model to Pick
Recommended AI Tools
Grammarly
Updated March 2026 · 12 min read · By PopularAiTools.ai
View Review →Google Imagen
Updated March 2026 · 11 min read · By PopularAiTools.ai
View Review →CapCut
Updated March 2026 · 12 min read · By PopularAiTools.ai
View Review →Picsart
Updated March 2026 · 11 min read · By PopularAiTools.ai
View Review →