Building a Retrieval-Augmented Generation (RAG) application using Llama-3 locally on your computer provides a powerful way to leverage natural language processing for a variety of tasks, from customer support to content creation, all without the need for internet connectivity. This setup is especially beneficial for developers looking to integrate advanced AI capabilities while ensuring privacy and reducing reliance on external APIs. Moreover, setting up this system is completely free, utilizing open-source libraries and tools. The steps outlined below will guide you through installing necessary software, preparing the application, and finally, deploying a functional web-based interface for user interaction.
Step-by-Step Guide
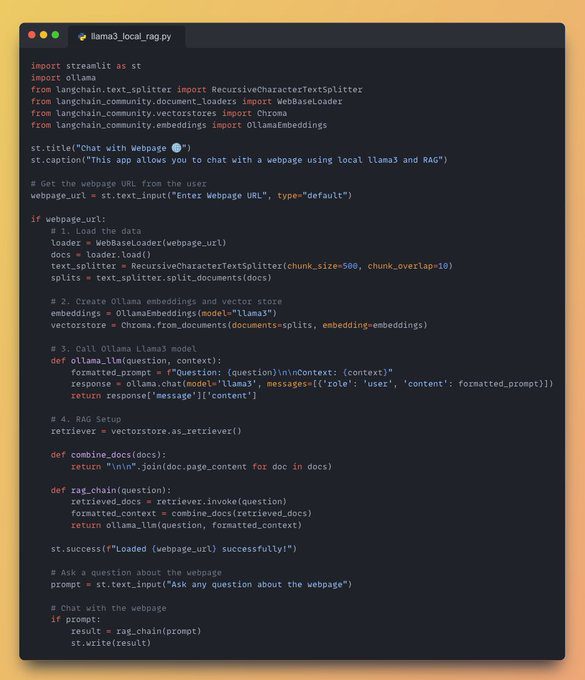
1. Install Required Python Libraries
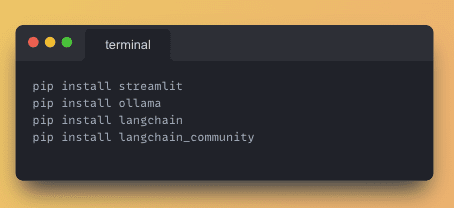
Execute the following command in your terminal to install the necessary libraries:
code
pip install streamlit langchain ollama chroma
2. Import Necessary Libraries
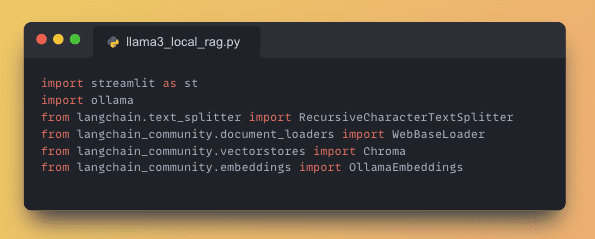
To set up your application, include the following Python libraries:
- Streamlit: For building the web interface.
- LangChain: To enable the RAG functionality.
- Ollama: For running the local large language model, Llama-3.
3. Set Up the Streamlit App
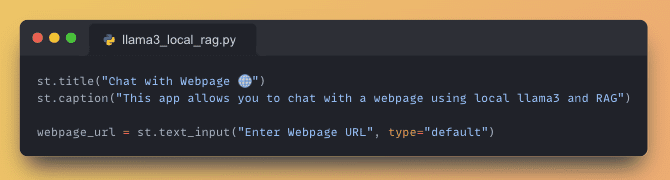
Use Streamlit to create a simple and intuitive user interface:
- Add a title to your application using
st.title(). - Collect the webpage URL from the user for processing.
4. Load and Process Webpage Data
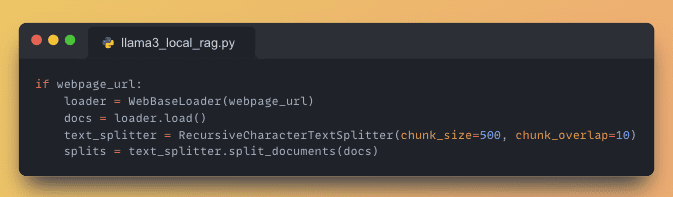
Utilize WebBaseLoader to load the webpage data, and then segment it into manageable chunks for further processing.
5. Create Ollama Embeddings
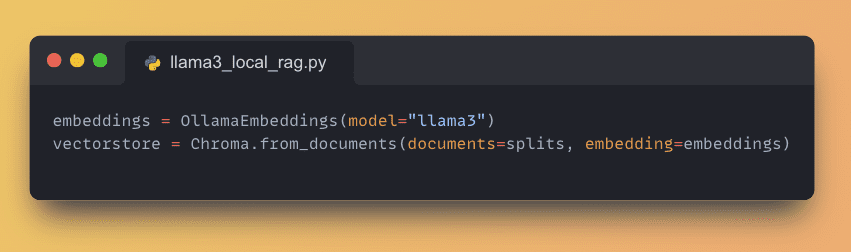
Use Chroma to generate embeddings for the processed data, creating a vector store for quick retrieval.
6. Define Local Model Interaction
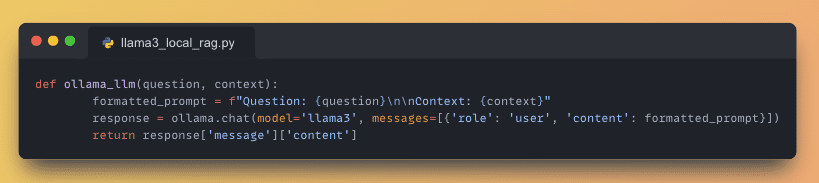
Implement a function to invoke the Ollama Llama-3 model locally, providing the necessary context for accurate responses.
7. Initialize the RAG System
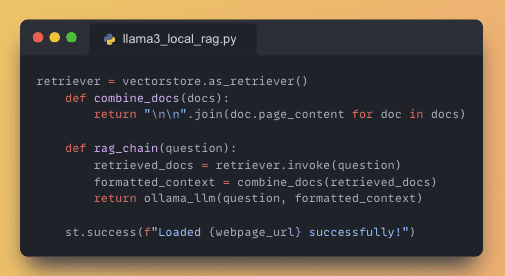
Set up the retrieval-augmented generation framework to enhance the model’s output with information retrieved from the processed data.
8. Interface for Querying
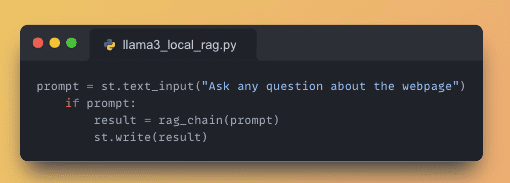
- Incorporate a text input field using
st.text_input()for users to pose questions. - Display the answers by retrieving the relevant information from the RAG system using
st.write().
Take Action:
Copy the provided code into your preferred Python editor like VSCode or PyCharm. Then, execute the command ‘streamlit run llama3_local_rag.py’ to see the application in action
Frequently Asked Questions (FAQ)
Q1: What is a RAG application?
A1: A Retrieval-Augmented Generation (RAG) application combines traditional language models with a retrieval system to enhance the model’s responses with information fetched from a provided dataset or content.
Q2: Why run Llama-3 locally?
A2: Running Llama-3 locally offers increased privacy, as data does not need to be sent over the internet. It also allows for customization and control over the computing resources used.
Q3: What are the benefits of using Streamlit in this setup?
A3: Streamlit is an open-source app framework that is particularly suited for quickly creating custom web interfaces for machine learning and data science projects, making it ideal for prototyping and deploying AI tools.
Q4: How does Chroma help in building a RAG application?
A4: Chroma is used for creating and managing vector embeddings, which are crucial for the retrieval component of a RAG application, facilitating faster and more accurate data retrieval.
Q5: Is there any cost associated with using these tools?
A5: No, all the tools and libraries recommended here, such as Streamlit, LangChain, Ollama, and Chroma, are open-source and free to use.

AI Tools Related Articles – Entrepreneurship and Productivity
Discover AI Integrations and Educational Resources
- AI Tool Categories & Integrations
- AI Courses for Enthusiasts and Professionals
- Submit a Tool to Popular AI Tools
- Advertise Your AI Solutions
Explore Featured AI Tools and Blogs
- Explore GPTs and Their Capabilities
- Featured AI Tools for Various Needs
- AI Blog for Latest News and Tips
- 9 Best AI Essay Writers of 2024
Dive Into AI Tool Categories and Reviews

