
NVIDIA GTC 2026: Everything Jensen Huang Just Announced
Yesterday’s GTC 2026 keynote was, without exaggeration, the most densely packed two hours we have ever seen from Jensen Huang. Where previous keynotes teased one or two flagship chips, this one dropped seven new chips in production, a roadmap stretching to 2028, orbital AI hardware, a walking Disney robot, and a partnership that could reshape how every enterprise deploys AI agents. We watched the whole thing so you don’t have to — here is every major announcement, explained.
Table of Contents
- The Vera Rubin Platform: Seven Chips, One Rack
- Vera CPU: Built From Scratch for Agentic AI
- Groq 3 LPU Integration: The Inference Game-Changer
- DLSS 5: Neural Rendering Meets Gaming
- Space-1: AI Leaves the Planet
- NemoClaw and the OpenClaw Partnership
- Disney Olaf Robot Demo: Physical AI Gets Real
- Feynman Architecture and Rosa CPU: The 2028 Roadmap
- Autonomous Vehicles: The ChatGPT Moment for Self-Driving
- Enterprise Partnerships and the $1 Trillion Outlook
- What This Means for AI in 2026 and Beyond
- FAQ
The Vera Rubin Platform: Seven Chips, One Rack
The headline product of GTC 2026 is the Vera Rubin NVL72, a full rack-scale AI supercomputer that integrates seven brand-new chips into a single system comprising 1.3 million components. Named after the astronomer whose work revealed dark matter, Vera Rubin is designed to be the backbone of next-generation AI factories.

The seven chips shipping inside the NVL72 rack are:
| Chip | Role |
|---|---|
| Rubin GPU | Next-gen accelerator for training and inference |
| Vera CPU | Custom ARM-based processor for agentic AI workloads |
| NVLink 6 Switch | Ultra-high-bandwidth chip-to-chip interconnect |
| ConnectX-9 NIC | Network interface for rack-to-rack communication |
| BlueField-4 DPU | Data processing unit for security and networking offload |
| Spectrum-X NIC | Ethernet networking optimized for AI clusters |
| Groq 3 LPU | Language Processing Unit for high-throughput inference |
NVIDIA claims the Vera Rubin NVL72 delivers 10x more performance per watt than its predecessor, the Grace Blackwell platform. That is not a typo — a full order-of-magnitude efficiency gain in a single generation. For data center operators already struggling with power budgets, this changes the economics of large-scale AI deployment overnight. See also: best AI coding tools in 2026.
Vera Rubin is scheduled to begin shipping to customers later this year, and Huang made it clear that production is already underway.
Vera CPU: Built From Scratch for Agentic AI
One of the most surprising reveals was the Vera CPU itself. This is not a rebadged ARM core. NVIDIA designed 88 custom cores from the ground up, calling them Olympus cores, each capable of running two simultaneous tasks through what the company calls Spatial Multithreading.
Here are the key specifications:
| Specification | Detail |
|---|---|
| Core Count | 88 custom Olympus cores |
| Multithreading | Spatial Multithreading (2 tasks per core) |
| Memory Type | LPDDR5X |
| Memory Bandwidth | Up to 1.2 TB/s |
| Efficiency Claim | 50% faster, 2x more efficient than traditional rack-scale CPUs |
NVIDIA positioned Vera as the first processor purpose-built for reinforcement learning and agentic AI. The emphasis on agentic workloads is deliberate — as AI moves from simple prompt-response patterns to long-running, multi-step autonomous agents, the CPU needs to handle constant context switching, tool orchestration, and parallel reasoning loops. Vera was designed for exactly that.
Groq 3 LPU Integration: The Inference Game-Changer
Perhaps the most headline-grabbing chip reveal was the Groq 3 Language Processing Unit (LPU) — NVIDIA’s first product born from its $20 billion asset acquisition of Groq in December 2025. Huang unveiled the Groq 3 LPU as a dedicated inference accelerator designed to sit alongside the Vera Rubin rack.
The Groq 3 LPX rack holds 256 LPUs and is purpose-built for high-throughput token generation. When paired with the Vera Rubin NVL72, the combined system delivers up to 35x higher tokens per second per megawatt compared to Blackwell-era hardware.
This is NVIDIA’s answer to the inference cost problem. Training massive models is one challenge, but serving them to billions of users at acceptable latency and cost is where the industry bottleneck has shifted. By integrating Groq’s deterministic inference architecture directly into the Vera Rubin ecosystem, NVIDIA is building inference efficiency into the platform from the ground up.
The Groq 3 LPU is expected to ship in Q3 2026.
DLSS 5: Neural Rendering Meets Gaming
Gamers got their moment too. NVIDIA announced DLSS 5, which represents a fundamental shift from upscaling to full 3D-guided neural rendering. Previous DLSS versions essentially took lower-resolution frames and intelligently upscaled them. DLSS 5 goes further — it combines traditional 3D computer graphics with generative AI to produce real-time, photorealistic 4K output on local hardware.
Huang described the approach as merging structured data from the 3D rendering pipeline with AI generation, resulting in visuals that are both “beautiful and controllable.” The key word there is controllable — unlike pure generative AI output, DLSS 5 stays grounded in the actual game geometry and lighting data, preventing the hallucination artifacts that plague purely AI-generated visuals.
Launch partners include Ubisoft, Bethesda, Capcom, Tencent, and Warner Bros. Games, with a target release window of Fall 2026. We expect this to be one of the defining features of the next-generation gaming experience.
Space-1: AI Leaves the Planet
In one of the keynote’s most visionary moments, Huang revealed the NVIDIA Space-1 Vera Rubin Module — hardware designed to bring AI data centers into orbit. This is not a concept slide. NVIDIA is actively developing radiation-hardened, power-optimized versions of the Vera Rubin platform for deployment on orbital infrastructure.
The Space-1 module offers up to 25x the AI compute of an H100 in a form factor engineered for the extreme constraints of space: limited power, thermal challenges, radiation exposure, and zero-gravity cooling requirements.
The applications are immediate and practical: real-time satellite imagery analysis, autonomous spacecraft navigation, orbital communications optimization, and on-board scientific data processing that eliminates the latency of downlinking raw data to Earth. For defense, telecommunications, and Earth observation companies, this announcement opens an entirely new market for accelerated computing.
NemoClaw and the OpenClaw Partnership
The agentic AI portion of the keynote centered on NemoClaw, NVIDIA’s enterprise-grade AI agent platform built on top of the open-source OpenClaw framework. NVIDIA partnered directly with OpenClaw creator Peter Steinberger to develop a version suitable for corporate deployment.
NemoClaw adds critical enterprise features to OpenClaw: See also: NemoClaw AI agent platform we covered earlier.
- NVIDIA OpenShell runtime for secure agent execution
- Policy enforcement and network guardrails
- Privacy routing to keep sensitive data on-premises
- Integration with NVIDIA NeMo and NemoTron open models
- Hardware-agnostic deployment (runs on any GPU, not just NVIDIA)
Huang emphasized that NemoClaw is fully open source. Users can tap any coding agent or AI model, deploy agents locally on their own hardware, and maintain complete control over their data. Pairing NemoClaw with DGX Spark and DGX Station systems provides what NVIDIA calls “the ultimate platform for locally developing and deploying autonomous, long-running agents.” See also: 61 AI agents already available on GitHub.
At GTC, NVIDIA ran a hands-on Build-a-Claw event from March 16-19 where attendees could customize and deploy always-on AI assistants using the NemoClaw stack.
Disney Olaf Robot Demo: Physical AI Gets Real
Huang closed the keynote with a showstopper: a life-size robotic Olaf from Disney’s Frozen walked onto the GTC stage, fully autonomous, navigating the environment and interacting with the audience in real time.
This was not a pre-programmed animatronic. The Olaf robot was powered by NVIDIA’s full physical AI stack:
- Newton physics engine for real-time physics simulation
- NVIDIA Omniverse for digital twin training
- Disney Research’s Kamino simulator — a GPU-based physics solver that trains robots across thousands of parallel environments
- NVIDIA Isaac for robotic perception and control
Walt Disney Imagineering shared that the robotic Olaf learned to walk, balance on a moving boat, and interact with guests entirely through simulation — trained in virtual environments before ever touching real hardware. The demo underscored Huang’s thesis that every robot in the future will be born in simulation first.
This partnership with Disney signals that physical AI is no longer a research project. It is heading to theme parks, retail environments, and public spaces in the near future.
Feynman Architecture and Rosa CPU: The 2028 Roadmap
Looking beyond Vera Rubin, Huang previewed the Feynman architecture, NVIDIA’s next-generation platform on track for 2028. Feynman advances every pillar of the AI factory: compute, memory, storage, networking, and security.
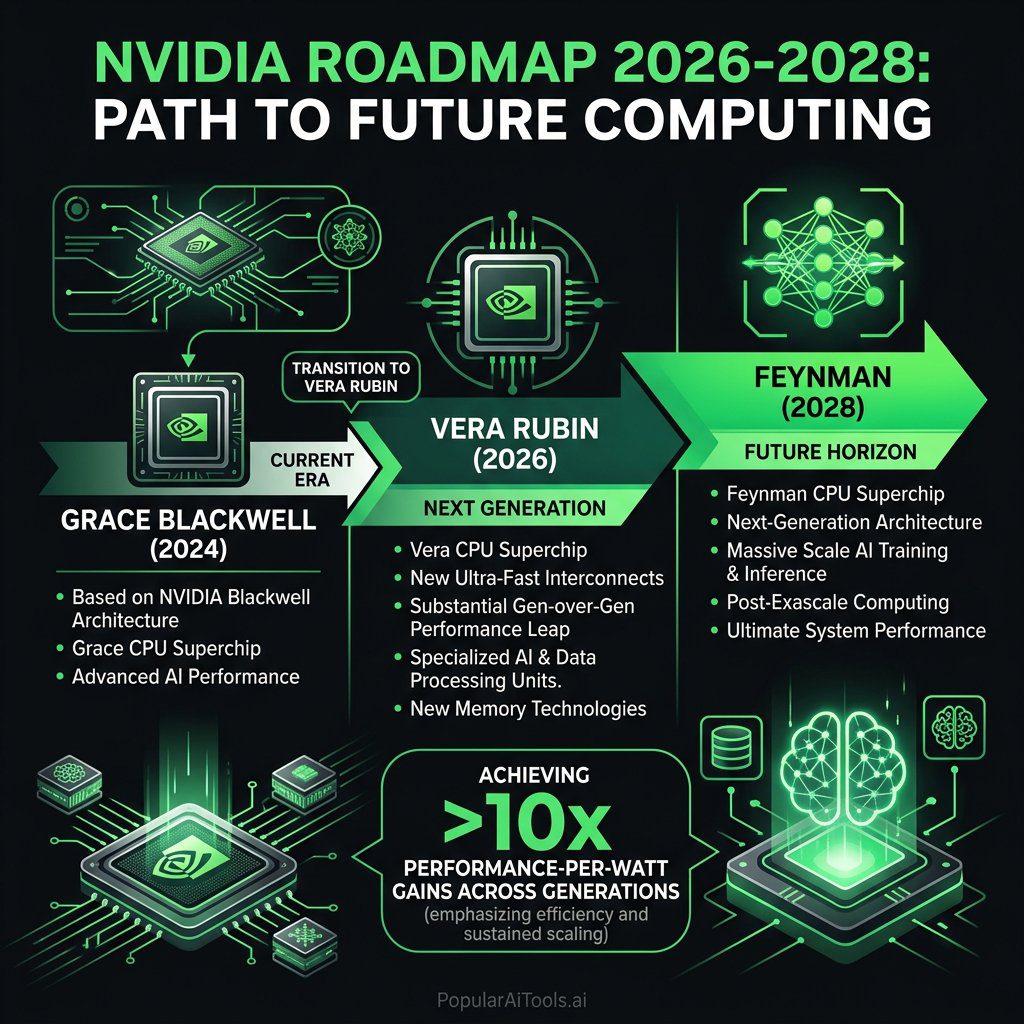
The Feynman generation includes:
| Component | Name/Detail |
|---|---|
| CPU | Rosa (named for Rosalind Franklin) |
| LPU | LP40 (next-gen Language Processing Unit) |
| DPU | BlueField-5 |
| NIC | CX10 |
| Interconnect | Kyber (copper and CPO scale-up) |
The Rosa CPU is designed to move data, tools, and tokens efficiently across the full stack of agentic AI infrastructure. While details were thin — this is a 2028 product — the naming and positioning suggest NVIDIA sees the CPU as increasingly central to the AI platform, not just a support chip for the GPU.
The message was clear: NVIDIA is not resting on Vera Rubin. The company has a multi-generational roadmap that keeps the pace of innovation at roughly one new architecture every two years.
Autonomous Vehicles: The ChatGPT Moment for Self-Driving
Huang declared that “the ChatGPT moment for autonomous driving is here” and backed it up with a wave of new partnerships. Nissan, BYD, Geely, Isuzu, and Hyundai are all building Level 4 autonomous vehicles on NVIDIA’s Drive Hyperion platform.
Additionally:
- Isuzu and China’s Tier IV are building autonomous buses using Drive Hyperion with NVIDIA’s AGX Thor robotic system chip
- Uber announced a new partnership with NVIDIA for autonomous ride-hailing infrastructure
- General Motors is working with NVIDIA to develop custom AI systems for autonomous vehicles, “putting AI in the car”
The convergence of better simulation (Omniverse), better inference (Groq 3 LPU), and better edge compute (AGX Thor) appears to have crossed a threshold where automakers are comfortable committing to Level 4 autonomy at production scale. Whether we see fully driverless fleets in 2027 remains to be seen, but the investment commitments are real.
Enterprise Partnerships and the $1 Trillion Outlook
Huang projected that purchase orders between Blackwell and Vera Rubin will reach $1 trillion through 2027 — double the $500 billion figure he cited last year. That number reflects both the scale of current AI infrastructure buildout and NVIDIA’s confidence that demand is accelerating, not plateauing.
Other enterprise highlights:
- IBM is partnering with NVIDIA to bolster its WatsonX AI platform, enabling companies to refresh their data multiple times per day at 83% lower costs
- Compal introduced a high-density HGX Rubin NVL8 integrated solution for enterprise data centers
- SanDisk announced storage optimizations specifically designed for the Vera Rubin platform
- Multiple telecom operators are exploring NVIDIA-powered RAN (Radio Access Network) reinvention for 5G and beyond
The breadth of partnerships across automotive, healthcare, telecom, enterprise IT, and defense signals that NVIDIA’s platform strategy is working. They are not just selling chips — they are selling the entire AI factory stack from silicon to software.
What This Means for AI in 2026 and Beyond
GTC 2026 made one thing abundantly clear: the AI industry is shifting from training to inference, from cloud to edge, and from software agents to physical robots. Every major announcement reinforced these three transitions.
The Vera Rubin platform and Groq 3 LPU address inference economics head-on. NemoClaw brings agentic AI to enterprise with privacy and security baked in. DLSS 5 pushes neural rendering to consumer hardware. Space-1 takes AI off-planet. And the Disney Olaf demo proved that physical AI is no longer a slide in a research presentation — it is a walking, talking reality.
For developers, enterprises, and creators, the takeaway is simple: the tools are here, the hardware is shipping, and the window to build on this platform is now.
FAQ
What is the NVIDIA Vera Rubin platform?
The Vera Rubin platform is NVIDIA’s next-generation rack-scale AI supercomputer, the successor to Grace Blackwell. It integrates seven new chips — including the Rubin GPU, Vera CPU, and Groq 3 LPU — into a single NVL72 rack system with 1.3 million components. It delivers 10x more performance per watt than Grace Blackwell and begins shipping later in 2026.
What is the Groq 3 LPU and why does NVIDIA have it?
The Groq 3 Language Processing Unit is a dedicated inference accelerator that NVIDIA gained through its $20 billion asset acquisition of Groq in December 2025. It is designed for ultra-fast token generation and, when paired with the Vera Rubin NVL72, delivers up to 35x higher tokens per second per megawatt compared to Blackwell. It ships in Q3 2026.
What is DLSS 5 and when does it launch?
DLSS 5 is NVIDIA’s next-generation rendering technology that combines traditional 3D computer graphics with generative AI for real-time photorealistic 4K output. Unlike previous DLSS versions that focused on upscaling, DLSS 5 uses 3D-guided neural rendering. It launches in Fall 2026 with support from Ubisoft, Bethesda, Capcom, Tencent, and Warner Bros. Games.
What is NemoClaw and how does it relate to OpenClaw?
NemoClaw is NVIDIA’s enterprise-grade AI agent platform built on top of the open-source OpenClaw framework. It adds policy enforcement, network guardrails, privacy routing, and the NVIDIA OpenShell runtime to make OpenClaw suitable for corporate deployment. It is fully open source and hardware-agnostic, meaning it runs on any GPU.
What is the Feynman architecture?
Feynman is NVIDIA’s next-generation AI platform architecture after Vera Rubin, on track for 2028. It includes the Rosa CPU (named for Rosalind Franklin), the LP40 next-gen LPU, BlueField-5 DPU, and Kyber interconnect. Feynman advances every pillar of the AI factory: compute, memory, storage, networking, and security.
Have you built an AI tool or discovered one that deserves more attention? We are always looking for the next breakthrough to feature. Submit your AI tool to PopularAiTools.ai and get it in front of thousands of readers who are actively searching for the best AI solutions available today.
External Resources
- NVIDIA GTC 2026 Official News Hub — NVIDIA’s official live blog with all GTC 2026 announcements
- HPCwire: NVIDIA Boasts 7 Chips in Production for Vera Rubin — Deep technical breakdown of the Vera Rubin platform
- Tom’s Hardware: NVIDIA GTC 2026 Keynote Live Blog — Comprehensive minute-by-minute coverage of the full keynote
