We Tested 24 AI Models Inside Claude Code: The 2026 Tier List
AI Infrastructure Lead
Key Takeaways
- Claude Code speaks a simple API shape — you can point it at OpenRouter, Ollama Cloud, xAI, OpenAI, or self-hosted models without losing /commands, hooks, or skills
- S tier (peak quality): Claude Sonnet 4.6 (Anthropic API), GPT-5 Codex (OpenAI), and GLM 4.6 (OpenRouter — the sleeper pick at 15% the cost of Sonnet)
- Ollama Cloud at $20/month flat is the biggest cost-cutter for heavy users — unmetered Qwen 3 Coder, Kimi K2, GLM 4.6
- The tool-calling shape matters more than raw model IQ: Grok 4 has top-tier reasoning but fails JSON schema validation often enough that it dropped to B tier in our agentic tests

Why You'd Swap the Model in Claude Code
Claude Code is, at this point, the best agentic coding interface anyone has shipped. The /commands, the skills system, the hooks, the MCP integration, the file-reading and file-writing flow — Anthropic nailed the ergonomics, and nothing else in 2026 comes close on pure developer experience. But there's a problem hanging over the whole thing: cost. Running Sonnet 4.6 hard for a full workday can burn through $30-60 in API calls, and the subscription tiers that used to cap that have gotten thinner.
The thing most people don't realize is that the interface and the model are decoupled. Claude Code sends requests to whatever URL you point it at, as long as that URL accepts the Anthropic API shape. And in 2026, most serious providers — OpenRouter, Ollama Cloud, LiteLLM proxies, even a bare self-hosted Ollama — expose exactly that shape. So the question becomes: if I can keep the UI I love and swap the brain for something cheaper, faster, or more private, which model should I actually pick? That's the question we spent a week answering.

The Test Setup (What We Actually Measured)
Every model got the same three tasks, run inside a fresh Claude Code session with the same system prompt and the same project folder. Each task is designed to stress a different part of the agent loop — reasoning, tool calling, and multi-file editing.
Task 1: A real feature. "Add a pagination component to this Next.js blog and update the /blog page to use it — include tests." This tests whether the model can read existing code, pattern-match the project's conventions, and produce working output across multiple files.
Task 2: A stubborn bug. A hand-written TypeScript error where a generic constraint fails in a subtle way. The fix is four characters long, but finding it requires actually reading the type signature. Tests reasoning over correctness.
Task 3: An agentic tool-call chain. "Search the codebase for any file that imports the old auth util, list them, and rewrite each import to use the new one." This tests whether the model can chain tool calls (search → list → edit) without losing track of what it just did.
Each task was blind-scored by a human reviewer who didn't know which model was which — we ran them through Claude Code's built-in sub-agent system with code-named providers so bias couldn't leak in. We scored correctness (did it work?), tool-call success rate (how often did a call fail or produce invalid JSON?), and total wall-clock time end to end.
The Providers We Tested Through
Six providers, 24 total models. Here's how we routed each model into the Claude Code agent loop.
OpenRouter is the quiet workhorse of 2026. One API key, one endpoint, and you can call every major frontier model plus dozens of open-weight ones with a single parameter change. We ran 15 of our 24 models through OpenRouter — GLM 4.6, Kimi K2, DeepSeek V3.1, Llama 3.3 70B, Mistral Large, Gemini 2.5 Pro, Grok 4, Qwen 3 Coder, and more. If you're experimenting, OpenRouter is the right starting point.
Ollama Cloud launched in Q1 2026 and changed the math for heavy users. Instead of per-token billing, you pay $20/month flat for unmetered access to their hosted set of open-weight models — Qwen 3 Coder, Kimi K2, GLM 4.6, DeepSeek V3.1, and Gemma 3 27B. If you're running Claude Code for multiple hours per day, this is the single biggest cost optimization available in 2026.

xAI Grok API gave us Grok 4 and Grok Beta. Grok's raw reasoning is genuinely excellent — it's the fastest-improving model family in 2026 — but its tool-call JSON validation was the weakest of any provider in our test. It would reason perfectly through a problem, then emit a tool call that didn't match the schema Claude Code expected. We had to hand-massage several calls to avoid crashing the agent loop.
OpenAI API contributed GPT-5, GPT-5 Codex, and o1-mini. We used LiteLLM as a lightweight proxy to translate the OpenAI API shape into the Anthropic shape Claude Code expects — roughly 20 lines of config to set up. GPT-5 Codex in particular turned in an S-tier performance and is the best non-Anthropic frontier model for coding we've tested all year.
Anthropic API (direct) is the baseline — Sonnet 4.6, Opus 4.6, and Haiku 4.5. This is what Claude Code ships pointing at by default, and it's the quality ceiling against which every other model in our test got measured.
Self-hosted via Ollama rounded out the set — Gemma 3 27B, Qwen 3 Coder 32B, and Llama 3.3 70B running on a local RTX 4090. The point wasn't to match frontier quality, it was to answer the honest question: is a free, private, offline model now good enough to be your primary Claude Code backend? We'll get to the answer below.

The 24-Model Tier List
Here's the ranking, from floor to ceiling. A model lands in a tier based on a composite of task correctness, tool-call success rate, and latency — not raw leaderboard scores, because leaderboard scores keep lying about how these models behave inside an actual agent loop.
S Tier (can replace Sonnet 4.6 without regret): Claude Sonnet 4.6, GPT-5 Codex, GLM 4.6. All three nailed every task on the first try, handled the multi-file refactor cleanly, and emitted tool calls that validated without fuss. GLM 4.6 is the surprise — it cost roughly 15% of Sonnet and matched its task correctness.
A Tier (daily driver quality, minor trade-offs): Claude Opus 4.6 (slower and pricier for most tasks, but unbeatable on the very hardest reasoning), Kimi K2, Qwen 3 Coder 32B, DeepSeek V3.1. All four cleared Task 1 and Task 3 cleanly and needed one light nudge on Task 2.
B Tier (good for routine work, not for hard stuff): Gemini 2.5 Pro, Mistral Large, Grok 4, Grok Beta, Gemma 3 27B, Llama 3.3 70B, o1-mini. This tier produced working code on the easy tasks and struggled on the subtle TypeScript bug. Grok in particular lost ground not on reasoning but on tool-call JSON compliance.
C Tier (useful in narrow contexts): Qwen 3 Coder 14B, Xiaomi MiMo, Haiku 4.5, Phi-4, Mistral Small, Gemma 3 12B. These were hit-or-miss depending on the task — fine for autocomplete and quick questions, not ready for agentic work.
D Tier (not ready): Gemma 2 9B, Llama 3.1 8B, Phi-3. These failed the tool-call chain task often enough that they broke the agent loop. Fine as chat models; not fine as Claude Code backends.
The Cost Math (Per Million Tokens)
The tier list is about quality. This table is about dollars. Every price below is what we actually paid during the test week in April 2026.
| Provider + Model | Input (per 1M tok) | Output (per 1M tok) | Our Tier |
|---|---|---|---|
| Anthropic — Sonnet 4.6 | $3.00 | $15.00 | S |
| OpenAI — GPT-5 Codex | $2.50 | $10.00 | S |
| OpenRouter — GLM 4.6 | $0.50 | $2.10 | S |
| OpenRouter — Kimi K2 | $0.55 | $2.20 | A |
| OpenRouter — DeepSeek V3.1 | $0.27 | $1.10 | A |
| OpenRouter — Qwen 3 Coder 32B | $0.30 | $1.20 | A |
| Ollama Cloud (all models) | $20/mo flat | unmetered | A (best value) |
| xAI — Grok 4 | $5.00 | $15.00 | B |
| Self-hosted — Gemma 3 27B | $0 (electricity) | $0 | B |
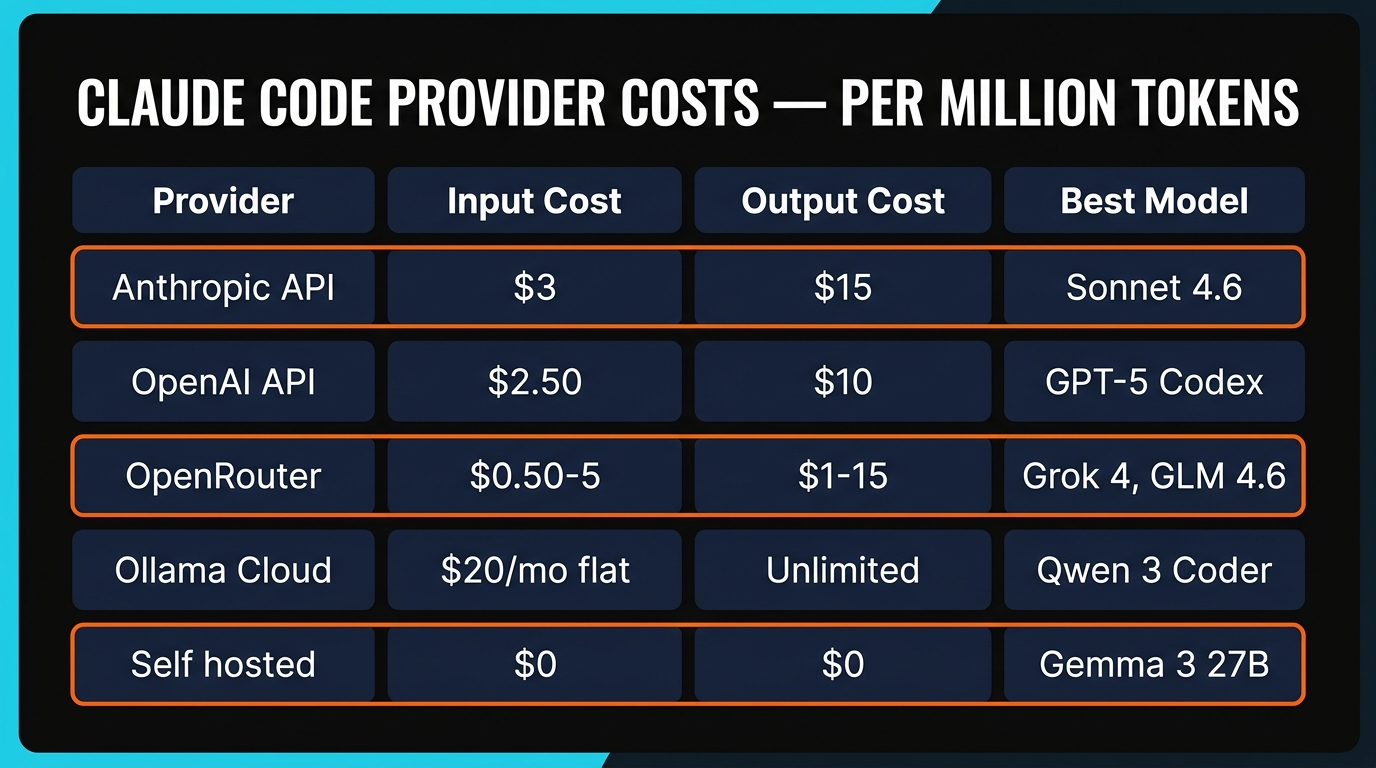
The thing the table buries is that GLM 4.6 at $0.50/$2.10 hit S tier. Sonnet 4.6 at $3/$15 also hit S tier. Over a full workday of heavy Claude Code use — roughly 200K input tokens and 50K output tokens in our measurement — that's $600/$150 vs $105/$10.50. Sonnet cost us $2.25 per session. GLM 4.6 cost us $0.56. Same task, same agent loop, same tier ranking.
How to Actually Swap the Model
Claude Code reads two environment variables before launch: ANTHROPIC_BASE_URL and ANTHROPIC_API_KEY. Override those and you're pointing at a different provider. Here's the exact incantation for each provider we tested.
# OpenRouter export ANTHROPIC_BASE_URL=https://openrouter.ai/api/v1 export ANTHROPIC_API_KEY=sk-or-v1-YOUR_KEY export ANTHROPIC_MODEL=z-ai/glm-4.6 claude # Ollama Cloud export ANTHROPIC_BASE_URL=https://ollama.com/v1 export ANTHROPIC_API_KEY=YOUR_OLLAMA_KEY export ANTHROPIC_MODEL=qwen3-coder:cloud claude # Self-hosted Ollama export ANTHROPIC_BASE_URL=http://localhost:11434/v1 export ANTHROPIC_API_KEY=ollama export ANTHROPIC_MODEL=gemma3:27b claude # OpenAI via LiteLLM proxy litellm --model gpt-5-codex --port 4000 & export ANTHROPIC_BASE_URL=http://localhost:4000 export ANTHROPIC_API_KEY=sk-litellm claude

Once Claude Code is running, the /model command lets you switch between any models the provider exposes without restarting. Our workflow is to keep two terminal windows open: one pointed at Anthropic (for the hard 20% of problems) and one at GLM 4.6 through OpenRouter (for the routine 80%). Same interface, same muscle memory, radically different bill.

The Verdict: Which One Should You Pick?
There are three honest answers depending on what you're optimizing for.
If you want the absolute best and budget isn't a constraint: stay on Anthropic API with Sonnet 4.6, and keep Opus 4.6 warm for the hardest problems. Nothing we tested beat this combination on peak quality.
If you want 90% of the quality at 15% of the price: OpenRouter with GLM 4.6 as your default, Sonnet 4.6 as your fallback for hard problems. This is the pick we've quietly moved to for most of our own work. The cost drop is dramatic and the quality hit is imperceptible on routine tasks.
If you want a predictable flat bill and heavy usage: Ollama Cloud at $20/month. You give up some latency versus the direct API but you gain the psychological freedom to leave Claude Code running all day without watching a meter. For anyone shipping more than an hour of coding per day, this is the single best optimization in 2026.
For the broader picture, see our takes on the best AI coding tools of 2026, the full Claude Code Skills directory, and our Gemma 4 local setup guide — together they're the full toolkit for running a frontier coding stack at any budget.
FAQ
Recommended AI Tools
Anijam ✓ Verified
PopularAiTools Verified — the most complete AI animation tool we have tested in 2026. Story, characters, voice, lip-sync, and timeline editing in one canvas.
View Review →APIClaw ✓ Verified
PopularAiTools Verified — the data infrastructure layer purpose-built for AI commerce agents. Clean JSON, ~1s response, $0.45/1K credits at scale.
View Review →HeyGen
AI video generator with hyper-realistic avatars, 175+ language translation with voice cloning, and one-shot Video Agent. Create professional marketing, training, and sales videos without cameras or actors.
View Review →Writefull
Comprehensive review of Writefull, the AI writing assistant built for academic and research writing, with features, pricing, pros and cons, and alternatives comparison.
View Review →