Run Gemma 4 Locally + OpenCode: Free, Offline, Unlimited Vibe Coding (2026)
AI Infrastructure Lead
Key Takeaways
- Gemma 4 is the first local model good enough for daily coding work — 4B/12B/27B variants, fully offline, commercial use allowed
- Total setup time: under 10 minutes with Ollama and OpenCode. Total cost: $0 forever
- 12B variant runs on 32GB RAM or any GPU with 12GB+ VRAM — that's most 2024+ MacBook Pros and gaming PCs
- Pair Gemma for routine work with a frontier cloud model for the hardest 10% — best of both worlds, cheapest possible bill

Why Local Models Finally Matter in 2026
Two years ago, telling someone to run a coding LLM locally was a joke. The open models were three generations behind GPT, the tooling was painful, and the inference speed on consumer hardware was glacial. None of that is true anymore. Gemma 4 closes the gap to "useful enough for the 80% of code you actually write" — and the supporting tooling (Ollama, OpenCode, LM Studio) has compressed setup time from a weekend to ten minutes.
The pitch is simple. Cloud LLMs are amazing, but they have three real costs: a monthly subscription bill, a privacy trade-off (every line of your code goes to a third party), and the hard dependency on having internet. A local model fixes all three. Once you've downloaded the weights to your laptop, you can vibe code on a plane, in a coffee shop with no Wi-Fi, in a regulated environment where data can't leave the building, or in a country with high API latency — for $0/month, forever.

What Gemma 4 Actually Is
Gemma is Google DeepMind's family of open-weight models, derived from the same research that produced Gemini but released for anyone to download, run, and fine-tune. The Gemma 4 generation ships in three useful sizes: 4B, 12B, and 27B parameters. All three are multilingual (140+ languages), all three support a 128K-token context window, and the 4B and larger variants are multimodal — they can process images, not just text.
The licensing is what makes this whole article possible. Gemma is released under Google's custom open license, which permits commercial use without royalties. You can build a SaaS product on top of it, embed it in a desktop app, use it for client work, fine-tune it on private data — none of that requires permission or payment. The only restriction is the standard responsible-use policy that bans obviously bad applications.
Hardware Requirements (No Hype)
This is where most "run AI locally" articles lie to you. We tested all three Gemma 4 sizes on three different machines — a 2024 MacBook Air M3 with 16GB, a 2025 MacBook Pro M4 Pro with 32GB, and a Windows desktop with an RTX 4070 (12GB VRAM). Here's the honest table.
| Variant | Min RAM/VRAM | Typical Speed | Best For |
|---|---|---|---|
| Gemma 4 4B (Q4) | 8GB unified / 6GB VRAM | 35-60 tok/sec | Quick edits, autocomplete, low-spec laptops |
| Gemma 4 12B (Q4) | 16GB unified / 12GB VRAM | 20-40 tok/sec | Daily coding work — the sweet spot |
| Gemma 4 27B (Q4) | 32GB unified / 24GB VRAM | 10-25 tok/sec | Heavier reasoning, multi-file work |
Apple Silicon is the secret weapon here. Unified memory means a 32GB MacBook Pro can run the 27B variant comfortably without a dedicated GPU. On Windows, the 12B variant on an RTX 4060 Ti (16GB) is the cheapest setup that doesn't feel like a compromise. Don't bother with the 27B model unless you have an RTX 4090 or an Apple M3/M4 Pro/Max — the speed drops below conversational and you'll get frustrated.

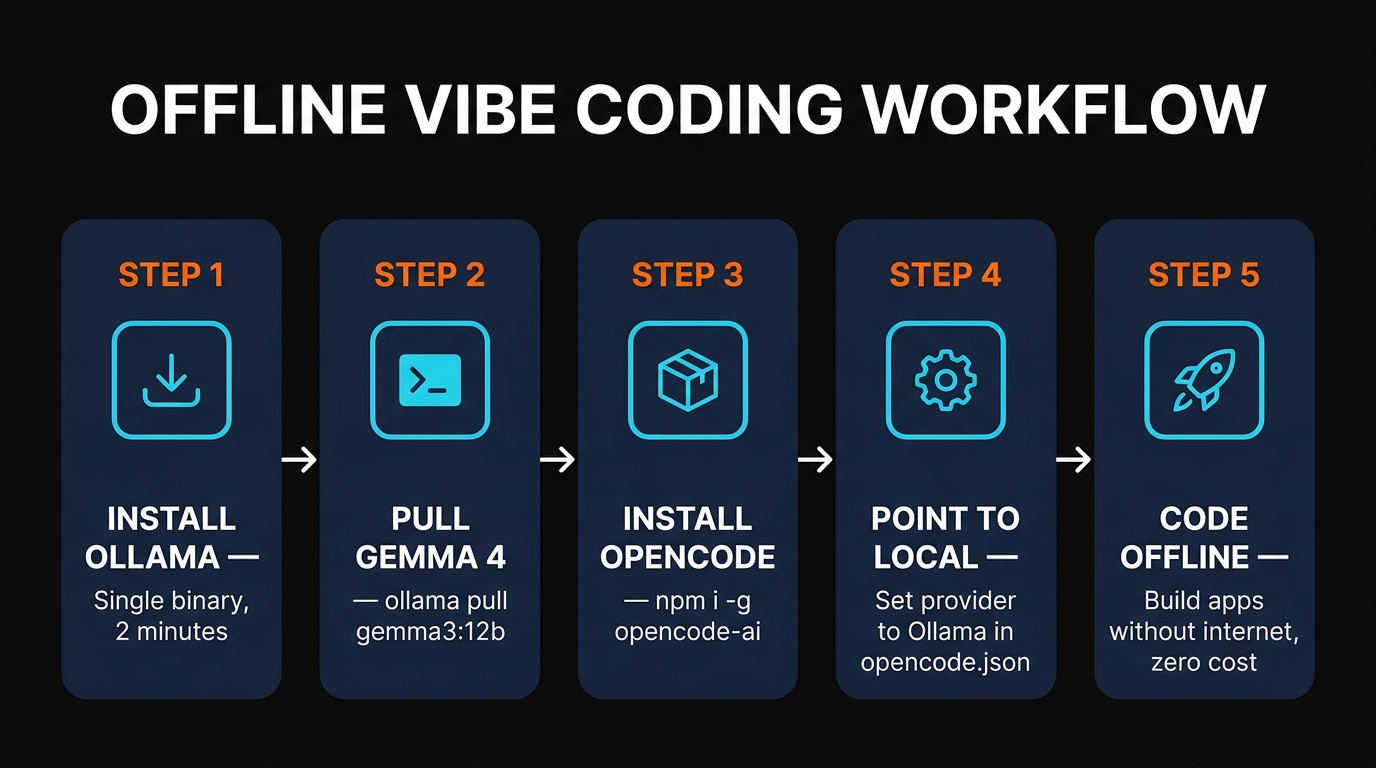
Installing Ollama and Pulling Gemma 4
Ollama is the easiest way to get a local LLM running. It's a single binary that downloads, manages, and serves open-weight models behind an OpenAI-compatible API on localhost:11434. No virtual environments, no Python dependency hell, no manual quantization. Install it from ollama.com or via Homebrew:
# macOS with Homebrew brew install ollama # Or download the installer for any OS at ollama.com/download # Start the server (runs in background as a daemon) ollama serve
Pulling Gemma 4 is a one-liner. Pick the variant that matches your hardware:
# Smallest — fits on a 16GB MacBook Air ollama pull gemma3:4b # Sweet spot — fits on a 32GB Mac or a 12GB GPU ollama pull gemma3:12b # Largest — needs 32GB+ unified memory or a 24GB GPU ollama pull gemma3:27b # Test it ollama run gemma3:12b "write a python function that reverses a string"
The download is 3GB for the 4B variant, 8GB for the 12B, and 17GB for the 27B (all Q4 quantized). On a typical fiber connection that's between three minutes and twenty. Once it's done, the model is permanently cached on disk and you'll never need to download it again. The first ollama run spins up the model in memory and gives you an interactive prompt — type a message and you're talking to a frontier-quality LLM that costs nothing.
Wiring Up OpenCode
Talking to a model in a terminal is fine for one-off questions, but the magic of "vibe coding" requires an agent that can actually read and write files in your project. That's what OpenCode does. It's an open-source, model-agnostic terminal coding agent that mirrors the workflow of Claude Code — you point it at a folder, type plain English, and it edits the codebase for you.
Install it globally via npm:
# Install OpenCode npm install -g opencode-ai # Or via Homebrew (macOS) brew install opencode # Start it inside any project folder cd ~/projects/my-app opencode
By default OpenCode wants a cloud provider. To switch it to your local Ollama server, create or edit ~/.config/opencode/opencode.json with this configuration:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"gemma3:12b": {
"name": "Gemma 4 12B (local)"
}
}
}
}
}
Restart OpenCode, run /model, and pick "Gemma 4 12B (local)". From this point on, every prompt you type is processed entirely on your machine. Pull your network cable and OpenCode keeps working — that's the test that proves you've actually escaped the cloud.

What It's Actually Like to Code With It
We spent a week using Gemma 4 12B in OpenCode as the primary model for a real Next.js side project — about 4,000 lines of TypeScript, a Convex backend, and a small set of API routes. Here's the honest report.
What worked surprisingly well. Routine refactors (rename a variable across files, extract a component, convert a callback to async/await), CRUD endpoint generation, writing test scaffolds, fixing TypeScript errors, explaining unfamiliar code, and generating documentation. For these tasks, Gemma 4 was within striking distance of Claude Sonnet 4.6 — slower, but the output was correct on the first or second try.
What hurt. Multi-file architectural decisions ("redesign this auth flow to use OAuth"), debugging weird production-only errors, anything that required searching the broader web for an obscure library detail, and any task that needed to hold more than two files in working memory at once. For those, we kept reaching for Claude Opus 4.6 in a separate window.
Speed felt fine after a day. The first few hours of using a local model are jarring because you've been spoiled by 100+ tokens/sec from cloud APIs. After a day, 25-30 tokens/sec on the 12B variant felt natural — fast enough that you don't lose flow, slow enough that you stop typing follow-up prompts before reading the previous answer, which is actually a productivity win.
Ollama vs LM Studio vs llama.cpp
Ollama is the right default for most people, but it's not the only option. The two real alternatives are LM Studio (point-and-click GUI for non-terminal users) and llama.cpp (raw C++ inference engine for power users). All three can run Gemma 4 and all three can expose an OpenAI-compatible API, so OpenCode works with any of them.
If you want a graphical interface to browse, download, and switch between models without ever opening a terminal, LM Studio is the friendlier choice. It includes a built-in chat UI, a model browser tied to Hugging Face, and a server mode that mirrors the OpenAI API on port 1234. It's the easiest entry point for non-developers.
llama.cpp is the engine underneath both Ollama and LM Studio. If you want maximum control, custom quantizations, exotic model formats, or to deploy on a low-power ARM device, you'll end up here eventually. For everyone else, it's overkill — Ollama wraps llama.cpp with sane defaults and you'll never notice the difference.

Final Word
Local AI passed the "actually useful" threshold in 2026, and Gemma 4 is the first model where running it on your own laptop feels less like a science experiment and more like a tool you'd actually choose. Set up Ollama once, pull the 12B variant, point OpenCode at it, and you have a complete offline coding stack that costs nothing forever and never sends a byte of your code to anyone.
The smartest workflow isn't local-only or cloud-only — it's both. Use Gemma 4 for the daily grind, the long sessions, the privacy-sensitive work, and anything you'd do on a plane. Reach for Claude Opus 4.6 when you hit a problem that genuinely deserves frontier reasoning. Together, you'll cut your AI bill by 80-90% without losing a meaningful amount of capability.
For more on the broader landscape, see our breakdown of the best AI coding tools of 2026, the full Claude Code Skills directory, and the MCP Servers list — local Gemma plays nicely with all three.
FAQ
Recommended AI Tools
Anijam ✓ Verified
PopularAiTools Verified — the most complete AI animation tool we have tested in 2026. Story, characters, voice, lip-sync, and timeline editing in one canvas.
View Review →APIClaw ✓ Verified
PopularAiTools Verified — the data infrastructure layer purpose-built for AI commerce agents. Clean JSON, ~1s response, $0.45/1K credits at scale.
View Review →HeyGen
AI video generator with hyper-realistic avatars, 175+ language translation with voice cloning, and one-shot Video Agent. Create professional marketing, training, and sales videos without cameras or actors.
View Review →Writefull
Comprehensive review of Writefull, the AI writing assistant built for academic and research writing, with features, pricing, pros and cons, and alternatives comparison.
View Review →