Claude Code + Pinecone 2.0: How to Give Claude Unlimited Memory (RAG Setup Guide)
AI Infrastructure Lead
Key Takeaways
- Claude Code's built-in memory caps at 200 lines — Pinecone gives you unlimited persistent vector memory
- Semantic search finds relevant past context by meaning, not keywords — dramatically better recall
- Free tier covers most individual workflows (2GB storage, 2M writes/month)
- Setup takes 10-15 minutes with a Claude Code skill that handles vectorization automatically

The Memory Problem
Claude Code has a memory system. It stores notes in markdown files with a MEMORY.md index. Sounds fine until you realize the index is capped at 200 lines. Line 201? Silently truncated. No error. No warning. Your carefully saved context from three months ago just disappears.
We hit this wall while managing a project with 50+ files and weeks of accumulated context. Every new session started with Claude re-discovering things we'd already discussed. It felt like working with someone who has amnesia — brilliant in the moment, but zero long-term recall.
The underlying issue is architectural. Claude Code's memory uses a 4-layer system: CLAUDE.md (project instructions), MEMORY.md (auto-memory index), individual memory files, and session state. But the search is grep-based — literal text matching only. If you stored "fixed the authentication bug in middleware" six months ago, a search for "auth issues in route handlers" returns nothing. The concepts are related, but grep doesn't understand meaning.
The solution is RAG — Retrieval-Augmented Generation — using a vector database. And in 2026, the fastest way to add RAG to Claude Code is Pinecone 2.0. Our Claude Code complete guide covers the basics — this article goes deep on the memory layer.
How RAG Actually Works
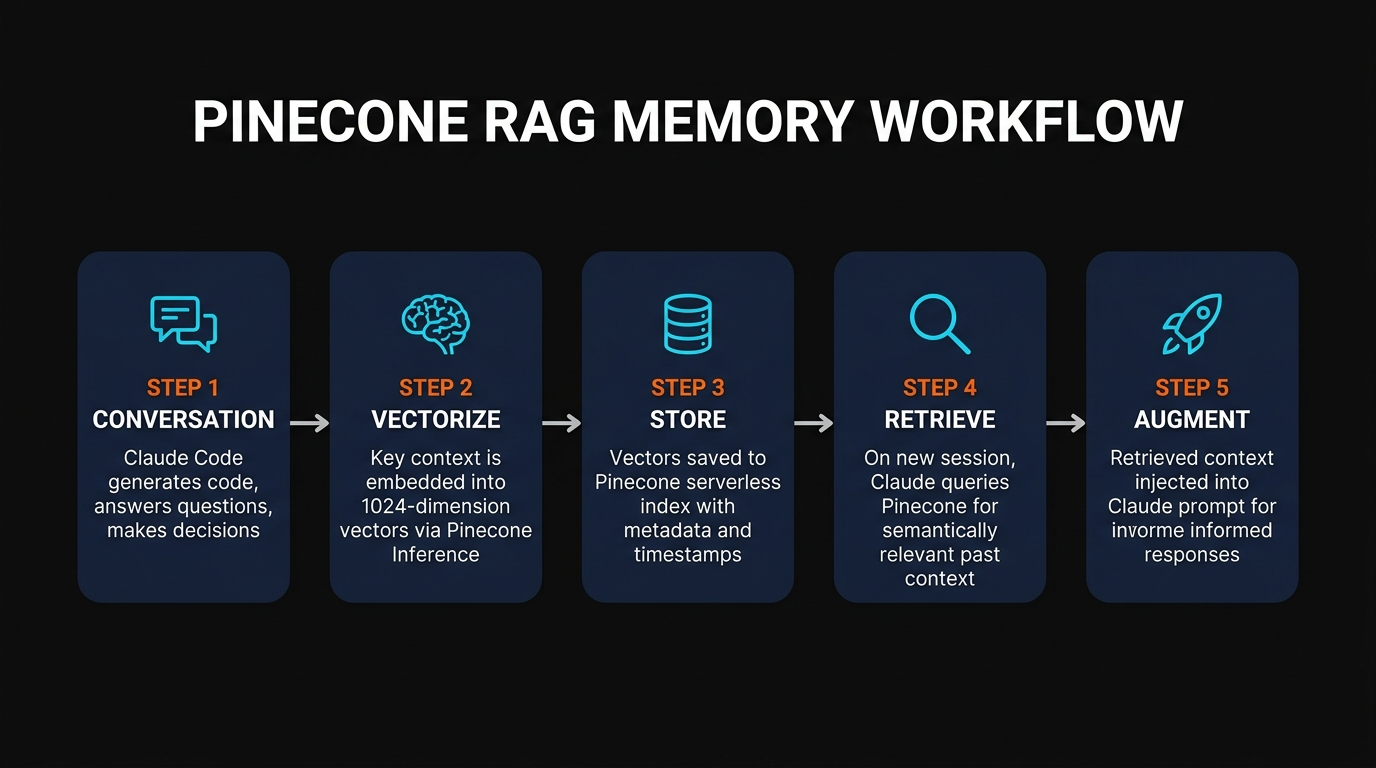
RAG sounds complicated but the concept is simple: before Claude answers your question, it searches a database for relevant context and injects it into the prompt. Instead of Claude relying only on what's in the current conversation, it can pull in relevant information from weeks or months of past interactions.
Here's how the pipeline works in practice:
- You say something to Claude — "Fix the payment webhook handler"
- Your query gets vectorized — converted into a 1024-dimension numerical representation (an "embedding") that captures the meaning
- Pinecone searches for similar vectors — finds past conversations, code snippets, and decisions that are semantically similar to "payment webhook handler"
- Relevant context gets injected — the top 5-10 most relevant past interactions are added to Claude's prompt as additional context
- Claude responds with full context — it now knows about the Stripe webhook refactor you did last month, the edge case with duplicate events, and the error handling pattern you decided on
The key difference from keyword search: semantic search understands meaning. "Payment webhook handler" matches "Stripe event processor" and "billing callback endpoint" — because they're conceptually related, even though they share zero words.
Setting Up Pinecone
The setup takes about 10 minutes. Here's the exact process:
Step 1: Create a Free Account
Go to pinecone.io and sign up. The Starter plan is free — no credit card required. You get 2GB storage, 2M write units/month, and 1M read units/month. For a single-developer Claude Code workflow, this is more than enough.
Step 2: Create an Index
An index is where your vectors live. Create one with these settings:
Index name: claude-memory Dimensions: 1024 (matches llama-text-embed-v2) Metric: cosine Cloud: AWS us-east-1 (free tier)
Step 3: Get Your API Key
In the Pinecone console, go to API Keys. Copy your key — you'll need it for the Claude Code skill configuration. Store it in your project's .env file.
Vectorizing Your Knowledge
Vectorization is the process of converting text into numerical embeddings that capture meaning. Pinecone 2.0 includes Pinecone Inference — built-in embedding models so you don't need a separate OpenAI or Cohere account just for embeddings.
The recommended model is llama-text-embed-v2 — 1024 dimensions, included in the free tier at 5M tokens/month. Here's what the code looks like:
from pinecone import Pinecone
pc = Pinecone("YOUR_API_KEY")
index = pc.Index("claude-memory")
# Embed and store a memory
embedding = pc.inference.embed(
model="llama-text-embed-v2",
inputs=["Fixed auth middleware to handle expired JWT tokens"],
parameters={"input_type": "passage"}
)
index.upsert(vectors=[{
"id": "memory-2026-04-09-001",
"values": embedding.data[0].values,
"metadata": {
"text": "Fixed auth middleware to handle expired JWT tokens",
"project": "my-saas-app",
"date": "2026-04-09",
"type": "code-fix"
}
}])
# Later: search by meaning
query_embedding = pc.inference.embed(
model="llama-text-embed-v2",
inputs=["authentication issues in route handlers"],
parameters={"input_type": "query"}
)
results = index.query(
vector=query_embedding.data[0].values,
top_k=5,
include_metadata=True
)
# Returns the JWT fix even though no words match!
The magic is in that last query. We searched for "authentication issues in route handlers" and got back "Fixed auth middleware to handle expired JWT tokens" — because the embeddings capture semantic similarity. Grep would have returned zero results.
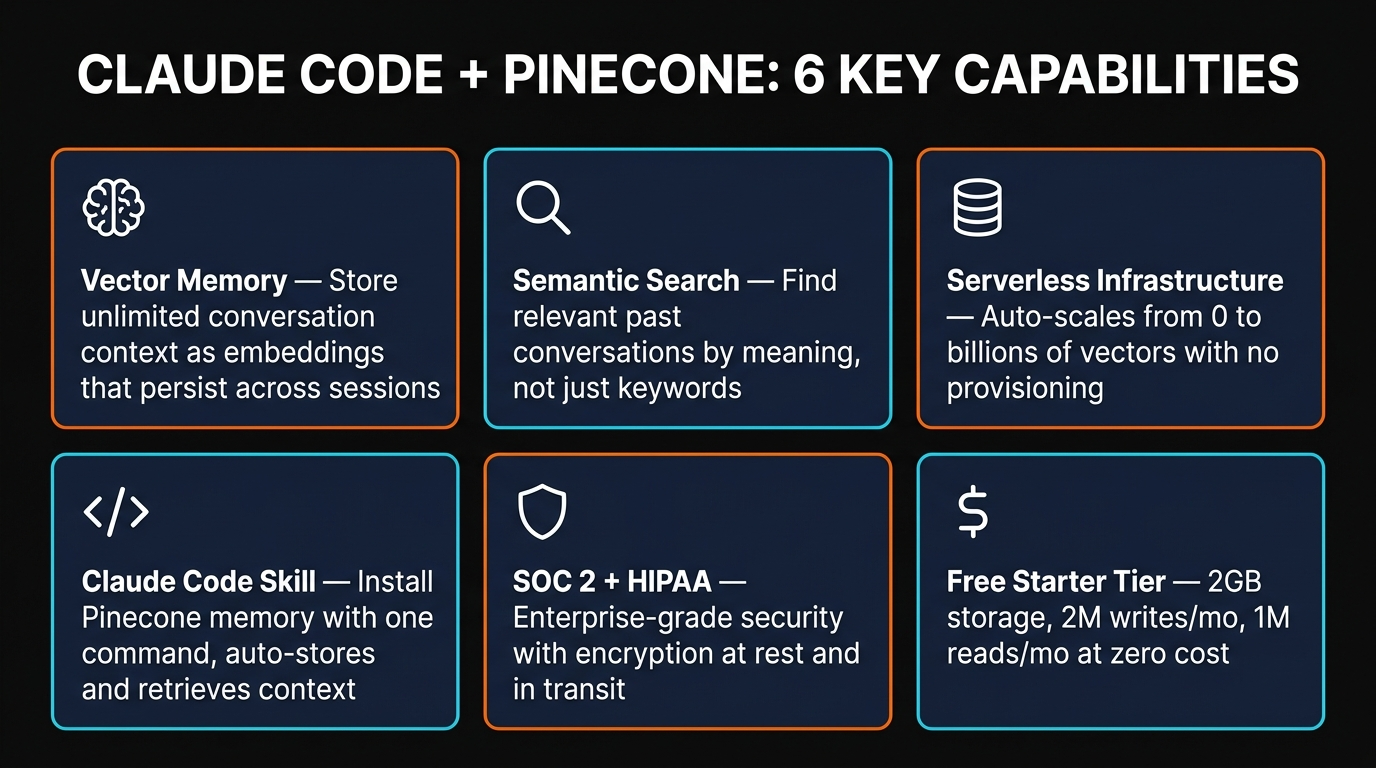
Claude Code Integration
There are two ways to connect Pinecone to Claude Code: a pre-built skill or a custom CLAUDE.md configuration. We tested both.
Option 1: Install the Vector Database Skill
The fastest approach — one command installs a Claude Code skill that handles vectorization and retrieval automatically:
npx skillfish add vector-database-skill
This skill supports Pinecone, Chroma, and pgvector. Configure it with your Pinecone API key and index name, and Claude Code automatically stores important context after each session and retrieves relevant memories at the start of new ones.
Option 2: Custom CLAUDE.md + Hooks
For more control, you can wire Pinecone into your Claude Code hooks. Add a Stop hook that vectorizes key decisions after each response, and a SessionStart hook that queries Pinecone for relevant context when a new conversation begins. This is what we use — it's more work to set up but gives you full control over what gets stored and retrieved.
The hook approach works particularly well with the auto-memory system we described in our Claude Code AutoDream memory guide. Combine both: CLAUDE.md for fast session rules, Pinecone for deep semantic recall.
What Gets Stored
Not everything should go into the vector database. We found the best results by storing:
- Architecture decisions — "We chose Convex over Supabase because of real-time subscriptions"
- Bug fixes and root causes — "CSS gradients broke because of blanket !important overrides in page.tsx"
- API patterns and gotchas — "Convex articles:update requires updatedAt or it silently fails"
- User preferences — "Client wants dark theme only, no emojis in code, tabs not spaces"
- File responsibilities — "page.tsx lines 235-310 handle article CSS — high-risk, read entire file before editing"
Don't store: raw code (it's in git), build output, temporary debugging steps, or anything that changes frequently. The vector DB should contain wisdom, not data.
Pinecone Pricing
Starter (Free)
- ✓ 2GB storage
- ✓ 2M write units/month
- ✓ 1M read units/month
- ✓ 5M embedding tokens/month
- ✓ Up to 5 indexes
Standard
- ✓ Unlimited storage
- ✓ Pay-as-you-go
- ✓ Multi-cloud (AWS/GCP/Azure)
- ✓ SAML SSO + RBAC
- ✓ HIPAA add-on available
Enterprise
- ✓ 99.95% uptime SLA
- ✓ Private networking
- ✓ Customer-managed encryption
- ✓ Audit logs
- ✓ Pro support included
Our recommendation: Start with the free Starter plan. The 2GB storage holds roughly 500K-1M text memories depending on metadata size. That's enough for years of individual Claude Code usage. Only upgrade to Standard ($50/mo) if you're running multiple projects, need team access, or process more than 2M writes/month.
Memory Alternatives Compared
| Solution | Search Type | Capacity | Cost | Best For |
|---|---|---|---|---|
| Pinecone RAG | Semantic (vectors) | Unlimited | Free - $50/mo | Large, long-running projects |
| CLAUDE.md + MEMORY.md | Grep (keyword) | 200 lines | Free (built-in) | Simple projects |
| Claude-Mem | File-based | Disk space | Free (open source) | Medium projects, no vector search |
| NotebookLM | Source-grounded | 300 sources/notebook | Free | Research, not code memory |
| pgvector (self-hosted) | Semantic (vectors) | Unlimited | $30-150/mo (hosting) | Already using Postgres |

Advanced Memory Tactics
Once the basic setup is running, there are patterns that make it significantly more powerful.
Namespaces for Project Isolation
Pinecone supports up to 1.7 million namespaces per index. Use one namespace per project. This keeps memories isolated — searching in the "saas-app" namespace won't return results from your "blog-site" project. On the free tier, you get 100 namespaces, which is plenty.
Metadata Filtering
Every vector can carry metadata — date, project, file path, memory type. Use this to filter searches: "Find memories about auth from the last 30 days" narrows results to recent, relevant context without wasting retrieval tokens on outdated information.
Combine with NotebookLM
The best stack we've found: Pinecone for code memory, NotebookLM for research memory. Pinecone stores your architecture decisions, bug fixes, and project context. NotebookLM stores your research sources, competitor analysis, and documentation. Claude Code queries both — Pinecone for "what have we built and decided" and NotebookLM for "what does the research say." Our NotebookLM integration guide covers the research side in detail.
Memory Decay
Not all memories age well. A bug fix from six months ago in code that's been refactored twice is noise, not signal. Add a timestamp to every vector and weight recent memories higher in retrieval. Some teams run a monthly cleanup that deletes vectors older than 90 days with low retrieval scores — keeping the index lean and relevant.
For more Claude Code workflow patterns including parallel agents and worktrees, see our agentic workflow guide.

Frequently Asked Questions
Recommended AI Tools
HeyGen
AI video generator with hyper-realistic avatars, 175+ language translation with voice cloning, and one-shot Video Agent. Create professional marketing, training, and sales videos without cameras or actors.
View Review →Writefull
Comprehensive review of Writefull, the AI writing assistant built for academic and research writing, with features, pricing, pros and cons, and alternatives comparison.
View Review →Opus Clip
In-depth Opus Clip review covering features, pricing, pros and cons, and alternatives. Learn how this AI video repurposing tool turns long videos into viral short-form clips.
View Review →Chatzy AI
Agentic AI platform for building and deploying conversational AI agents across WhatsApp, website chat, and other digital channels. No-code builder with knowledge base training.
View Review →