Claude Opus 4.7 Review 2026: What It Can Actually Do Now
AI Infrastructure Lead
⚡ Key Takeaways
- 87.6% SWE-bench Verified — up from 80.8% on Opus 4.6. Beats GPT-5.4 and Gemini 3.1 Pro on production coding.
- 3x more production tasks resolved on Rakuten-SWE-Bench vs Opus 4.6, with a third of the tool errors.
- 2,576px vision input — 3.75 megapixels, more than triple the old limit. Real screenshots, diagrams, and UI mocks finally work.
- New xhigh effort, Task budgets, /ultrareview — three new knobs specifically for long-running agentic workflows.
- Same price as Opus 4.6 — $5 input / $25 output per million tokens. Upgrading is a free quality bump.
- What's actually new in Opus 4.7
- The benchmark numbers (and which ones matter)
- /ultrareview — the feature everyone is talking about
- 2,576px vision — why resolution matters for agents
- xhigh effort & task budgets
- Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro
- Pricing & availability
- Pros and cons
- Verdict — who should upgrade
- FAQ

Every time Anthropic ships a new Opus, the same question lands in our inbox: is it actually worth switching? Opus 4.6 was solid. It shipped features, it passed review, it mostly stopped arguing with us about tool calls. So when Opus 4.7 dropped on April 16, 2026, we didn't expect the jump to feel this big.
We spent 48 hours hammering it — running /ultrareview on messy legacy codebases, feeding it 2,500px architecture diagrams, chaining 40-step agentic workflows in Claude Code, and comparing side-by-side against GPT-5.4 and Gemini 3.1 Pro. This review is what we found: the benchmark wins, the real-world gotchas, what's changed in Claude Code, and whether you should upgrade your model config today.

What's actually new in Opus 4.7
Most model updates are a list of benchmark wins nobody can feel. Opus 4.7 is different — three of the changes are things you'll notice inside the first hour.
First, long-horizon agentic runs no longer collapse in the middle. Opus 4.6 had a habit of losing the thread around step 25 of a multi-step task, either repeating a tool call or hallucinating a file path. Anthropic explicitly targeted this: Opus 4.7 posts a 14% improvement on complex multi-step workflows while using fewer tokens and producing roughly a third of the tool errors.
Second, vision is finally useful for real work. The input limit jumped from roughly 768px on the long edge to 2,576px — about 3.75 megapixels. That's the difference between "I sort of see your diagram" and "I can read the labels on your ERD." Opus 4.7 hit 98.5% on visual-acuity benchmarks, up from 54.5% on 4.6.
Third, it passes "implicit-need" tests — tasks where the model must infer which tool to use without being told. This sounds small. It's not. It's the thing that makes the difference between an agent that needs hand-holding and one you can actually leave alone for twenty minutes.

The benchmark numbers (and which ones matter)
Benchmarks are a sport, and every vendor cherry-picks. Here's the honest read.
The headline number everyone is quoting is 87.6% on SWE-bench Verified — up from 80.8% on Opus 4.6. That jump is real and matches our own experience: tasks that used to require a retry now land first try. But SWE-bench Verified is a curated subset, and it's been saturating. The more interesting number is SWE-bench Pro at 64.3%, a harder benchmark designed to resist contamination — Opus 4.7 leads GPT-5.4 (57.7%) and Gemini 3.1 Pro there by 6-7 points.
On Rakuten-SWE-Bench, which measures real production tickets, Opus 4.7 resolved 3x more tasks than 4.6 — the single biggest quality-of-life delta we've seen between model generations. On GPQA Diamond (graduate-level science), it's at 94.2%, clearing 90% for the first time in the Claude line. CursorBench — which measures real IDE-inside completion quality — jumped from 58% to 70%.

The benchmark nobody is covering enough: tool error rate. Opus 4.7 produces about one-third the tool errors of 4.6 on long agentic runs. If you've ever watched a Claude agent misquote a function signature for the fifth time in a loop, that stat will matter to you more than any SWE-bench number.
/ultrareview — the feature everyone is talking about
/ultrareview is a new Claude Code slash command. On paper it's "a better code review." In practice it's the first code review tool we've used that catches the class of bugs that only appear when two files interact.
Run /ultrareview on a branch and Opus 4.7 dispatches four specialist sub-agents in parallel: one for security, one for logic, one for performance, and one for style. Each has its own system prompt and reads the diff independently. The main agent synthesizes their findings into a single report grouped by severity.
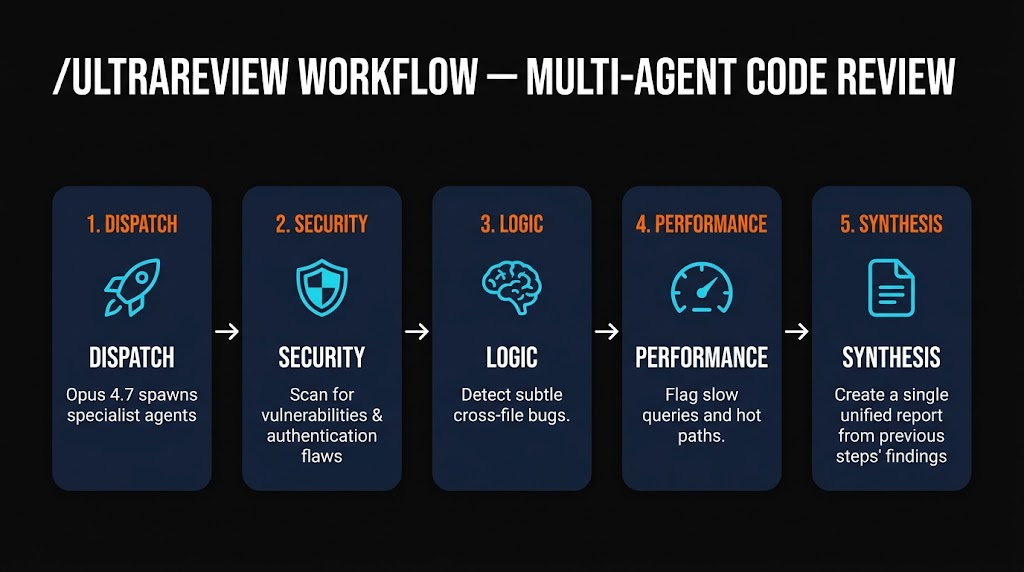
We ran it against a 2,400-line PR that had already passed GitHub Copilot review and a human pair. It flagged two real bugs: a race condition in a cache warmup routine and a subtle auth bypass in a middleware refactor that only triggered under a specific header combination. Both were the kind of cross-file reasoning that linters and single-pass review consistently miss.
The catch: it's slow. A thorough /ultrareview on a ~2K-line diff takes 3-5 minutes and burns meaningful tokens because you're paying for four parallel agents plus the synthesizer. This is why Task budgets exist — more on those below.
2,576px vision — why resolution matters for agents
The vision upgrade is the sleeper feature. The old 768px long-edge limit meant every architecture diagram you pasted got downsampled to the point of near-uselessness. Text labels blurred, arrow directions inverted, and asking Opus to reason about your schema was roulette.
At 2,576px you can feed Opus 4.7 a full screenshot of a Figma board, an ERD export, a Sentry stack trace, or a dashboard screenshot and it actually reads the labels. We pasted a 2,400x1,600 architecture diagram — the kind you'd normally have to hand-annotate — and asked "which service is missing a timeout?" It found it. On 4.6, that question got a polite "I can't clearly read the labels."
This unlocks two workflows specifically: computer-use agents (where the agent screenshots its own desktop to decide what to do next) and design-to-code (where you paste a mock and ask for the React component). Both were marginal on 4.6. Both are genuinely usable on 4.7.
xhigh effort & task budgets
Opus 4.7 adds two new knobs for controlling cost and quality on long runs.
xhigh effort slots between the existing high and max reasoning levels. Our take after a day of testing: use xhigh as your default for agentic work and reserve max for the hardest planning or debugging tasks. max produces slightly better reasoning but triples latency, which matters when an agent is making 40 tool calls.
Task budgets (public beta) let you set a token ceiling on a single agentic run. The model gets told "you have X tokens total across thinking and tool calls" and paces itself accordingly. This is the thing that makes /ultrareview budget-safe: you cap it at, say, 200K tokens and it won't silently burn through a million on a stubborn diff.
Practical tip: if you're using Opus 4.7 in Claude Code, set a default Task budget in your project config. It's the single best way to avoid an overnight run that returns a 12-figure bill.

Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro
We ran the same 20 tasks across all three models — half agentic coding, half reasoning, the rest vision and long-context. Here's the honest split.
| Workload | Winner | Margin |
|---|---|---|
| Agentic coding (Claude Code / Cursor) | Opus 4.7 | Clear (+6-8% SWE-Pro) |
| Raw reasoning / math proofs | GPT-5.4 | Narrow |
| Long-context research (1M+ tokens) | Gemini 3.1 Pro | Clear on context size |
| Vision (diagrams, dashboards) | Opus 4.7 | Large (2,576px) |
| Tool-use reliability (40+ steps) | Opus 4.7 | Clear (1/3 error rate) |
| Raw speed / latency | Gemini 3.1 Pro | Fastest at equivalent quality |
Short version: if your work is writing, reviewing, or running software engineering tasks with agents, Opus 4.7 is the best model in the world right now. For document-crunching research at scale, Gemini's 1M+ context is still the right tool. For raw reasoning, GPT-5.4 is still marginally ahead on the hardest puzzles.
Quick check: key upgrades in Opus 4.7
Pricing & availability
Here's the part that made this review easy: pricing is identical to Opus 4.6.
Input tokens
Output tokens
Prompt caching
Available across every major surface: Claude.ai (free/Pro/Max/Team), the Anthropic API under claude-opus-4-7, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. GitHub Copilot added the model to its chat picker the same day.
For Claude Code users, upgrading is one line:
claude --model claude-opus-4-7Or in your project's .claude/settings.json:
{
"model": "claude-opus-4-7",
"defaultEffort": "xhigh"
}

Pros and cons
Strengths
- ✓ Long-horizon reliability. 1/3 the tool errors of 4.6 on 40+ step runs.
- ✓ Vision that actually works. 2,576px input unlocks real design-to-code and diagram reasoning.
- ✓ /ultrareview catches real bugs. Cross-file logic and security issues single-pass reviewers miss.
- ✓ Free upgrade. Same price as 4.6 — no excuse not to switch.
- ✓ Task budgets are a safety net. Finally lets you run agentic jobs without bill anxiety.
Weaknesses
- × Context still capped at 200K. Gemini 3.1 Pro's 1M+ window is still unmatched for whole-repo research.
- × /ultrareview is slow. 3-5 min on a 2K-line diff. Not a replacement for fast lint/CI checks.
- × Max effort is overkill 95% of the time. Use xhigh as default — max triples latency for marginal gain.
- × Still no native video input. Vision is image-only — Gemini still leads on video understanding.
- × AI Design Tool didn't ship. Hinted at in pre-launch briefings, now listed as "pending."
Verdict — who should upgrade
If you're using Opus 4.6 in Claude Code, Cursor, or any agentic pipeline, upgrade to 4.7 today. The price is identical, the tool-error rate is a third of what it was, and /ultrareview alone is worth the switch for anyone shipping to production.
If you're still on Sonnet 4.6 for cost reasons, Opus 4.7 is still 5x more expensive on output — but with xhigh effort and Task budgets you can finally use it for the hard 10% of your workload without blowing your budget on the easy 90%.
The one group that shouldn't rush: if you're crunching multi-hundred-page documents in one shot, stay on Gemini 3.1 Pro for now. 1M+ context still beats a smarter model with a smaller window.
Our take: Opus 4.7 is the first post-launch model in the 4.x line where we stopped double-checking every tool call. That's the quietly important shift — not the SWE-bench headline, but the fact that we finally trust it on a 40-step run.
Quick check: when to use what
Frequently Asked Questions
claude-opus-4-7), Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry from day one.high and max. We recommend it as the default for agentic workloads — it's noticeably more deliberate than high without the 3x latency penalty of max./ultrareview. Unless you have a pinned evaluation pipeline, change model to claude-opus-4-7 today.
Recommended AI Tools
HeyGen
AI avatar video creation platform with 700+ avatars, 175+ languages, and Avatar IV full-body motion.
View Review →Kimi Code CLI
Open-source AI coding agent by Moonshot AI. Powered by K2.6 trillion-parameter MoE model with 256K context, 100 tok/s output, 100 parallel agents, MCP support. 5-6x cheaper than Claude Code.
View Review →Undetectr
The world's first AI artifact removal engine for music. Remove spectral fingerprints, timing patterns, and metadata that distributors use to flag AI-generated tracks. Distribute on DistroKid, Spotify, Apple Music, and 150+ platforms.
View Review →Anijam ✓ Verified
PopularAiTools Verified — the most complete AI animation tool we have tested in 2026. Story, characters, voice, lip-sync, and timeline editing in one canvas.
View Review →