GLM 5.2 in Claude Code: The Complete Setup Guide
AI Infrastructure Lead
TL;DR
GLM 5.2 in Claude Code is the most credible cheap Opus alternative available right now. 756B MoE parameters, 128K context, Anthropic-API-compatible via Z.ai — drop one JSON config file into your project and your bill drops by 5-15x with barely noticeable benchmark regression for everyday coding tasks.
Table of Contents
- What Is GLM 5.2?
- Why GLM 5.2 in Claude Code Is a Big Deal
- What GLM 5.2 Can Do Inside Claude Code
- When You Still Need Opus 4.7
- Benchmarks: GLM 5.2 vs Opus 4.7 vs Sonnet 4.6
- Pricing: The 5x Cost Argument
- Storm Research: The Killer Workflow
- Renting vs Owning Your Model
- Claude Code GLM 5.2 Setup (90 Seconds)
- When to Switch Per Project
What Is GLM 5.2?
Running glm 5.2 in Claude Code is now a realistic daily-driver setup — and that sentence would have sounded delusional eighteen months ago. GLM 5.2 is the flagship open source language model from Zhipu AI, released via their Z.ai platform in mid-2026. It is a Mixture-of-Experts model with 756 billion total parameters and a 128K token context window (extendable). Weights are openly downloadable from HuggingFace at zai-org/GLM-5-2 and from ModelScope.
What makes GLM 5.2 relevant to Claude Code users specifically is the compatibility layer Z.ai built on top of it. Their API gateway exposes the exact same request/response format as Anthropic's API. That means Claude Code's entire toolchain — Bash, Read, Edit, Write, Grep, Glob, subagent dispatch — works without modification. You are not shimming anything. You are just pointing the env vars at a different endpoint.
Self-hosting the full model requires 8x A100 or H100 GPUs. Quantized variants bring that requirement down substantially. For most developers, the Z.ai API is the right entry point — you get full-weight inference without the hardware bill.
Why GLM 5.2 in Claude Code Is a Big Deal
The short version: GLM 5.2 costs $0.40 per million input tokens and $1.60 per million output tokens via z ai. Claude Opus 4.7 costs $15 input / $75 output. That is a 37x and 47x gap respectively — or roughly 5-15x in typical mixed-task workloads.
The longer version: cost asymmetries of this magnitude change what you are willing to automate. When a coding session costs $0.80 instead of $8, you stop rationing Claude Code invocations. You run verification passes you would have skipped. You fan out multiple parallel research subagents. You let it write the README without guilt. That is not a marginal improvement — it is a workflow change.
"The question is never which model is technically best. The question is which model lets you do the most work per dollar before it matters that the best model is slightly better."
For the vast majority of Claude Code tasks — refactors, code review, documentation, multi-file edits, writing tests — GLM 5.2 benchmarks within 3-9 points of Opus 4.7. That gap closes further when you account for the fact that at 5x the budget, you run more verification passes anyway.
What GLM 5.2 Can Do Inside Claude Code
The tool-use compatibility layer is full-featured. Inside Claude Code, GLM 5.2 handles:
- Multi-file refactors and codebase analysis — it reads the dependency graph, understands cross-file concerns, and executes surgical edits across dozens of files in a single pass
- Full agentic loops — Read, Edit, Write, Bash, Grep, and Glob tool calls all work identically to Anthropic-hosted models
- Subagent dispatch for parallel exploration — the
CLAUDE_CODE_SUBAGENT_MODELenv var routes spawned subagents to GLM 5.2 as well - Markdown and documentation generation — PRs, READMEs, inline JSDoc, changelog entries
- Long-form research synthesis — the 128K context window fits entire codebases plus research notes in a single context
- Writing and iterating on tests — unit, integration, and e2e test generation from spec or from existing code
The model's MoE architecture means it activates only the relevant parameter slices per token — inference is faster than the raw parameter count implies, and latency at the Z.ai endpoint is competitive with Sonnet 4.6 for most coding-length responses.
When You Still Need Opus 4.7
I am not going to tell you GLM 5.2 matches Opus 4.7 everywhere. It does not. The benchmark gaps are real and they map onto specific task types. Reach for Opus 4.7 when:
- Complex multi-step reasoning with intermediate verification — proving program correctness, deep system design, novel algorithm derivation where each step depends on the last being right
- Adversarial and red-team scenarios — Anthropic's RLHF on safety edge cases is more mature
- Long-running agentic loops with 50+ turns — Opus 4.7 maintains plan coherence over very long contexts more reliably
- Highly specialized domains — if Anthropic specifically targeted your use case in training (e.g. certain medical coding, certain legal reasoning), the RLHF advantage shows
The practical rule: if the task has a clear objective function and a finite state space (most coding tasks), GLM 5.2 is good enough. If the task requires building and maintaining a mental model over many turns with no clear success signal until the end, keep Opus 4.7 in reserve. You can run both — the config below shows how to switch per-project rather than globally.
Benchmarks: GLM 5.2 vs Opus 4.7 vs Sonnet 4.6
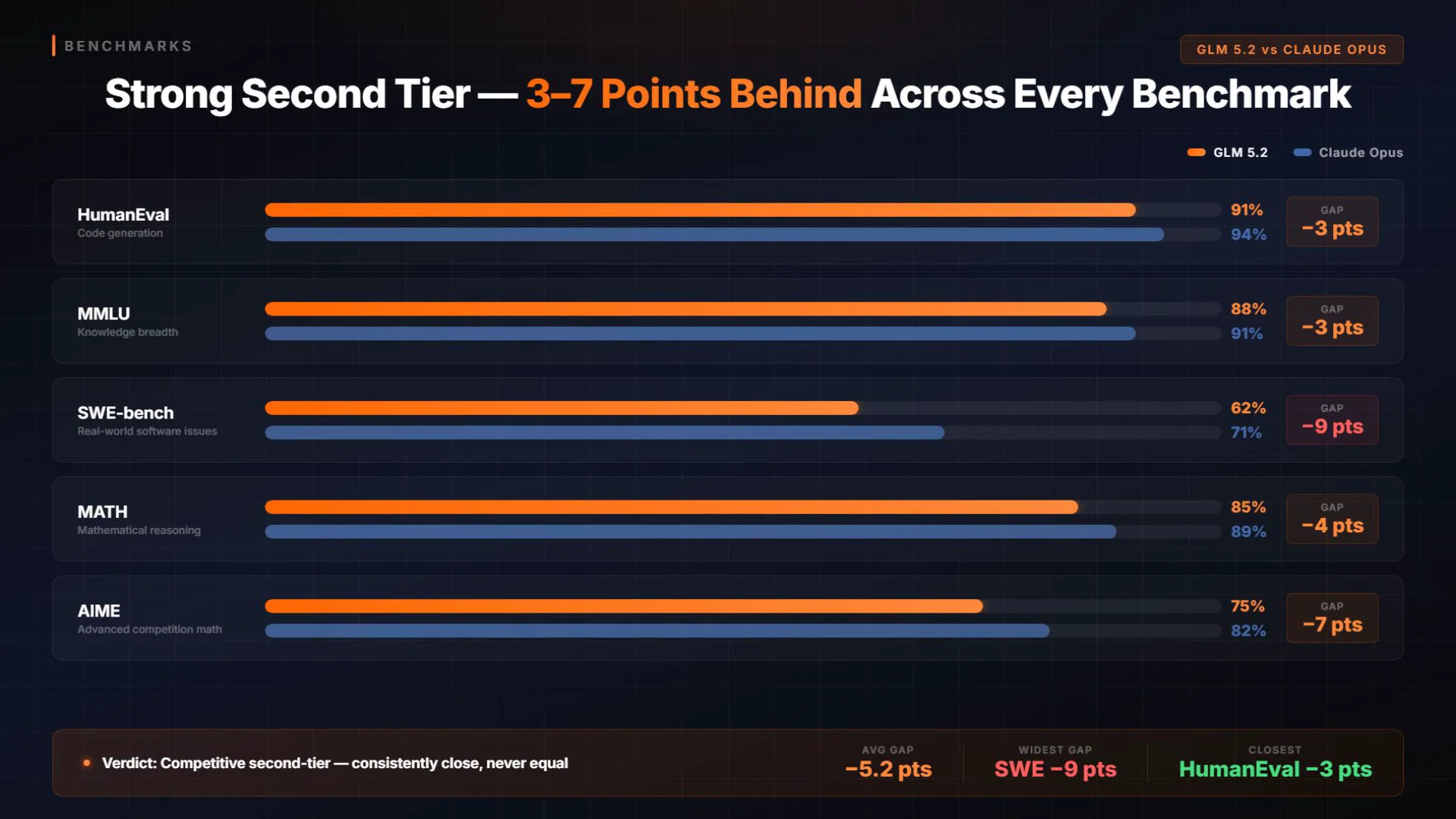
These are approximate public benchmark scores as of mid-2026. They should inform your model-switching heuristic, not replace it — benchmark conditions rarely match production coding tasks exactly.
The SWE-bench gap (-9pp) is the one worth paying attention to. That benchmark specifically tests agentic code editing on real GitHub issues — the most direct proxy for Claude Code workloads. GLM 5.2 at 62% is competitive with Sonnet 4.6 (60%) but meaningfully below Opus 4.7 (71%). On pure reasoning tasks like MMLU and HumanEval the gap narrows to 3pp — essentially noise for daily coding use.
Pricing: The 5x Cost Argument
Concrete math: a typical Claude Code session with a 30K output token build — say, refactoring a module and generating tests — costs about $2.25 on Opus 4.7 at $75/M output. The same session on GLM 5.2 costs $0.048 in output tokens plus about $0.04 in input. Call it $0.09 all-in versus $2.25+. Run ten sessions a day and that is $0.90 versus $22.50. Per month: $27 versus $675.
This math is why GLM 5.2 is the first open source language model that makes the conversation about "good enough vs best" actually worth having. Previous open-weight models were cheaper but not close enough. The benchmark gaps on GLM 5.2 are narrow enough to justify the trade for most workloads.
Storm Research: The Killer Workflow
The price asymmetry unlocks a specific workflow pattern I call storm research: fan out 8-10 parallel subagents to explore a problem space simultaneously instead of exploring it sequentially.
With Opus 4.7, parallel subagents are theoretically supported but economically punishing. Spawning 8 parallel research agents at $75/M output is the kind of thing you do only when the task is critical. With GLM 5.2 at $1.60/M output, that same fan-out costs 1/47th as much. You do it routinely.
What storm research looks like in practice inside Claude Code:
- Agent 1-2: Read every file in the target module, build a dependency map
- Agent 3-4: Search for all callers of the affected functions across the codebase
- Agent 5-6: Read test files, identify coverage gaps, draft new test cases
- Agent 7-8: Research the external API or library involved, pull docs and changelog
- Agent 9-10: Grep for error patterns, check similar past refactors in git log
All 10 run in parallel. The orchestrator collects results and synthesizes a refactor plan with full context. Wall-clock time: similar to a single sequential agent. Information density: 5-10x higher. Cost at GLM 5.2 rates: still cheaper than two Opus 4.7 sequential passes.
Set CLAUDE_CODE_SUBAGENT_MODEL in the config below to ensure every spawned subagent also uses GLM 5.2 — otherwise the orchestrator routes subagents to whatever default model Claude Code would have used.
Renting vs Owning Your Model

There is a useful mental model for thinking about the AI model market right now: renters and owners.
Renters use closed-source models via API — Opus 4.7, GPT-4o, Gemini Ultra. Best capability at each price tier, zero infrastructure overhead, but you are locked into the provider's pricing, model deprecations, and terms of service. The provider can change the model under you at any time.
Owners use open-weight models — via an API gateway like z ai, a third-party host, or full self-hosting. Less per token, weights don't disappear if the company pivots, you can fine-tune on your codebase, you have full optionality on where inference runs.
GLM 5.2 is the first open source language model that makes ownership credible at near-flagship capability. Previous open-weight models (Llama 3, Mistral, earlier GLM versions) were materially behind the closed frontier. GLM 5.2's benchmark scores sit between Sonnet 4.6 and Opus 4.7 on most coding tasks. That is a different conversation entirely.
The Z.ai gateway is the practical starting point for most teams. You get owned-model economics (low cost, no lock-in risk) with rented-model convenience (no GPU fleet, no quantization decisions). If your usage scales to the point where GPU costs are cheaper than API fees, the weights are there to self-host — same model, same outputs.
Claude Code GLM 5.2 Setup (90 Seconds)
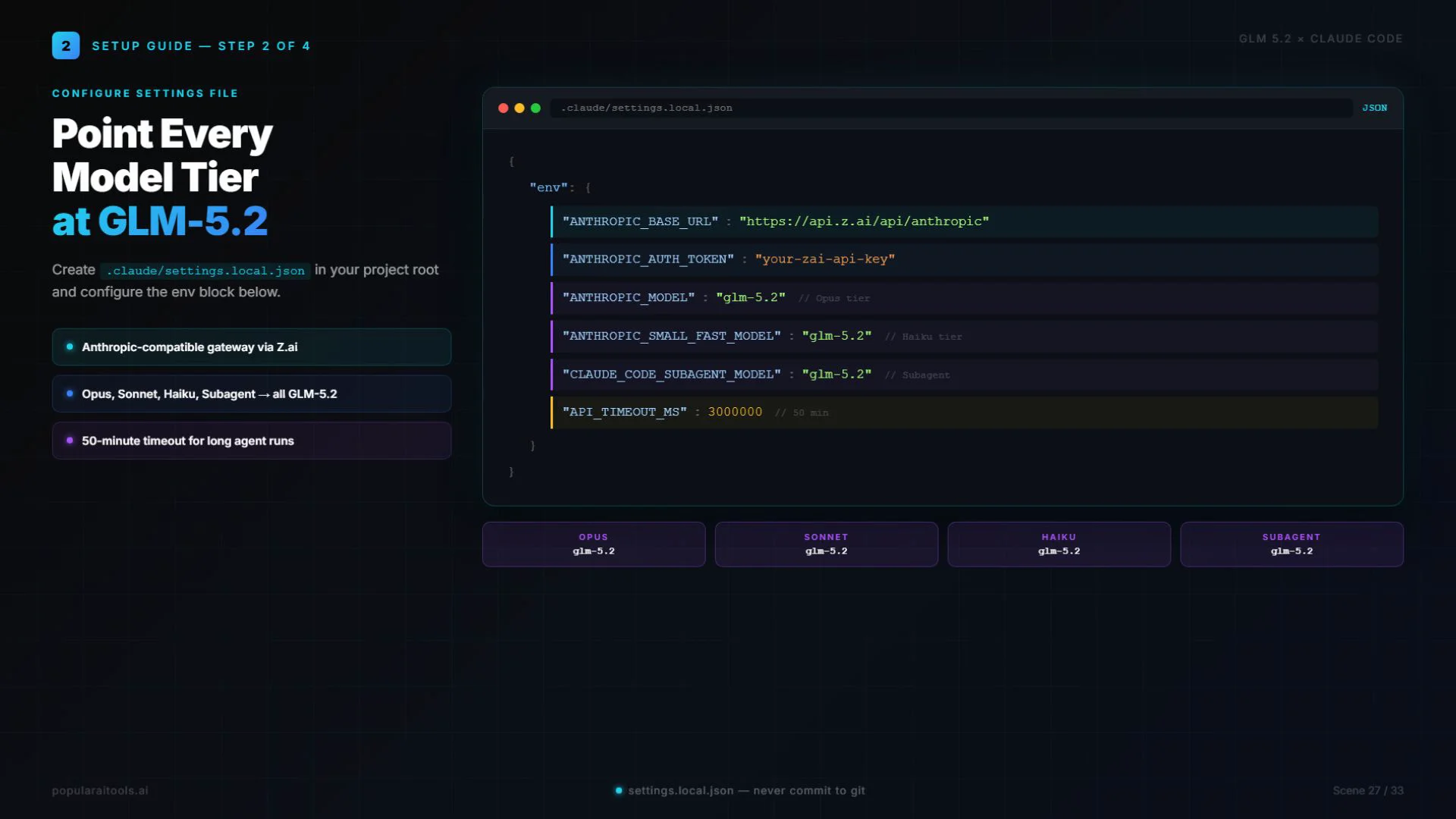
This is the exact config for running glm 5.2 in Claude Code. Four steps.
Step 1 — Sign up for Z.ai
Go to https://z.ai/, create an account, and generate an API key from your dashboard. The key will look like a standard bearer token.
Step 2 — Create the settings file
In your project root, create or edit .claude/settings.local.json. This file is local-only and should be gitignored. Paste the following config:
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.z.ai/api/anthropic",
"ANTHROPIC_AUTH_TOKEN": "your-z-ai-api-key-here",
"ANTHROPIC_API_KEY": "",
"API_TIMEOUT_MS": "3000000",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.2",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.2",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-5.2",
"ANTHROPIC_SMALL_FAST_MODEL": "glm-5.2",
"CLAUDE_CODE_SUBAGENT_MODEL": "glm-5.2"
}
}Step 3 — Replace the placeholder
Swap your-z-ai-api-key-here with your actual Z.ai key. Leave ANTHROPIC_API_KEY as an empty string — the base URL override takes precedence and Claude Code does not require a valid Anthropic key when an alternate base URL is set.
Step 4 — Restart Claude Code
Quit and reopen Claude Code. The settings.local.json file is picked up automatically at startup. Run a quick test — try /status or ask it to read a file — and verify you get a response. If you see an auth error, double-check that your Z.ai key is correct and that you have remaining quota on your account.
Note on API_TIMEOUT_MS: The 3,000,000ms (50 minute) timeout is intentional for long agentic loops. Z.ai's inference can be slower than Anthropic's hosted endpoints for very large context requests. If you hit timeout errors on shorter tasks, this value is not the problem — check your network or Z.ai account status instead.
When to Switch Per Project
The settings.local.json file is per-project, which means you can maintain different model configs for different repos. Here is how to think about the split:
A clean workflow: keep GLM 5.2 as your project default for the 80% of tasks, and maintain a separate settings.local.json.opus file you can swap in when you hit a genuinely hard problem. It takes 10 seconds to rename the file and restart.
Final Verdict
GLM 5.2 is not better than Opus 4.7. It is 5-15x cheaper and close enough that for most Claude Code workloads the difference does not show up in your output quality — only in your bill.
If you currently use Claude Code as a serious tool rather than an occasional helper, you are likely spending $50-200+ per month on Opus 4.7 or Sonnet 4.6 API costs. Switching your project defaults to GLM 5.2 for everyday work could cut that to $10-30 without meaningfully degrading the work product on refactors, documentation, test generation, and standard feature development.
The Z.ai setup takes ninety seconds. The weights are open so you are not locked in. The benchmarks are honest — there is a real gap on SWE-bench (-9pp), and complex reasoning tasks still favor Opus. But for the majority of agentic coding work, this is the most credible cheap Opus alternative available right now, and the storm research workflow alone justifies the switch for anyone running parallel subagents regularly.
Set up the config. Run it for a week on your normal workload. See if you notice the difference in output — and whether the difference (if any) is worth the cost delta. That is the only benchmark that matters for your specific project.
Related Articles
- → Claude Code Tips & Tricks: The Developer's Field Guide
- → The Best Claude Code Skills Worth Installing in 2026
- → Open-Claude: How to Run Any Model in Claude Code
- → Ollama + Claude Code: The Cheapest Local Setup Guide
- → DeepSeek V4 + Claude Code: Full Setup & Comparison
- → Claude Code Mastery Levels: Where Are You?
Know an AI tool we haven't covered?
Submit it to PopularAiTools.ai and we'll review it for the community.
Submit an AI Tool →PopularAiTools.ai
The definitive directory for AI tools that actually ship
1,000+ tools reviewed, benchmarked, and categorized. Filter by use case, price, and API availability. Updated weekly.
FAQ
What is GLM 5.2?
GLM 5.2 is the flagship open source language model from Zhipu AI, released via Z.ai in mid-2026. It uses a Mixture-of-Experts architecture with 756 billion total parameters and a 128K token context window. Weights are publicly downloadable from HuggingFace and ModelScope.
How does GLM 5.2 compare to Claude Opus 4.7?
GLM 5.2 scores within 3-9 percentage points of Opus 4.7 on major benchmarks (HumanEval 91% vs 94%, MMLU 88% vs 91%, SWE-bench 62% vs 71%) while costing roughly 5-15x less per token. Opus 4.7 still leads on complex multi-step reasoning and adversarial tasks.
Is GLM 5.2 really open source?
Yes. GLM 5.2 weights are openly downloadable from HuggingFace under the zai-org/GLM-5-2 repository and from ModelScope. Full self-hosting requires 8x A100 or H100 GPUs for the full model; quantized variants run on smaller hardware.
How much does GLM 5.2 cost per million tokens?
Via Z.ai's API gateway, GLM 5.2 costs $0.40 per million input tokens and $1.60 per million output tokens as of mid-2026. Claude Opus 4.7 costs $15 input / $75 output — roughly 37-47x more expensive per token.
Can I use GLM 5.2 with Claude Code?
Yes. Z.ai provides an Anthropic-API-compatible gateway, so you point Claude Code at https://api.z.ai/api/anthropic and set your Z.ai API key. A single .claude/settings.local.json config file is all you need — no code changes, no wrappers.
Do I need to change my workflow to use GLM 5.2?
Minimal changes. Add or edit .claude/settings.local.json in your project root with the config shown in this guide, sign up for a Z.ai API key, and restart Claude Code. Your existing slash commands, hooks, and agents all continue working unchanged.
Is GLM 5.2 better than DeepSeek V4 or Qwen?
It competes in the same tier. GLM 5.2 is specifically optimized for tool-use and agentic workflows, which gives it an edge in Claude Code scenarios. The right choice depends on your specific task mix — coding tasks favor GLM 5.2, while some reasoning benchmarks still favor DeepSeek V4. Test both on your own workload before committing.
Recommended AI Tools
Wondershare Repairit
Hands-on review of Wondershare Repairit (2026): AI-powered file repair for videos, photos, documents, audio, and Outlook email. Pricing, scenarios, comparison with Stellar, EaseUS Fixo, Yodot.
View Review →Wondershare Dr.Fone
After months of real-world use, Dr.Fone has become my go-to mobile rescue kit. AI-powered recovery, transfer, unlock, and repair across iOS and Android, with success rates that genuinely surprised me.
View Review →Wondershare RecoverIt
After six months of putting Wondershare RecoverIt through real recovery jobs (formatted SSDs, dead SD cards, crashed drives) it has earned a permanent spot in my toolkit. Here is the honest, detailed take.
View Review →Emergent.sh
Build production-ready apps in hours, not weeks. Full-stack with auth, payments, hosting included. $20-200/mo pricing.
View Review →