GLM 5.2 vs Opus 4.8 vs GPT 5.5: Real Cost Comparison (Tested 2026)
AI Infrastructure Lead
TL;DR — Live Test, June 2026
We ran three real coding tasks against GLM 5.2, Opus 4.8, and modeled GPT 5.5 with live-fetched pricing from each vendor's official page on test day. GLM 5.2 came in 2.0-2.8x cheaper than Opus 4.8 and 2.3-2.8x cheaper than GPT 5.5 on every task, even though GLM 5.2 produced longer outputs. The Z.ai Coding Plan subscription (with our 10% off link below) makes the gap even wider.
Table of Contents
- What We Tested and Why
- The Headline Math: $/MTok Compared
- Methodology: How We Measured
- Task 1 — Small Refactor (Rename Across Files)
- Task 2 — Medium Debug (Off-by-One Pagination)
- Task 3 — Large Feature (OAuth Token Refresh)
- The Z.ai Coding Plan: When Subscription Beats Per-Token
- When You Still Want Opus 4.8 or GPT 5.5
- Monthly Burn Scenarios at Real Usage
- Final Verdict
What We Tested and Why
There are too many AI coding model comparisons that quote pricing pages and call it done. We wanted to do the inverse — run identical coding prompts through the actual APIs, capture the actual input and output tokens from each response, and multiply those by live-fetched pricing on the test date. No estimates. No "typical workloads." Just three concrete tasks, three models, real numbers.
The headline answer is that GLM 5.2 via Z.ai is the most aggressive cost position currently available at frontier-adjacent capability. Opus 4.8 holds the quality crown for hard reasoning tasks. GPT 5.5 is similar to Opus 4.8 in price band but 20% more expensive on output. The question for any developer is not "which is best" — it is "which one do I default to, and when do I pay the premium." The cost data below answers the first half of that question definitively.
Reader Offer — Stackable 10% Off
Save 10% on the Z.ai Coding Plan with code HNP8DREH6R
Stacks on top of the annual (-30%) and quarterly (-20%) plan discounts already shown on the Z.ai pricing page. Plans start at $12.60 per month effective.
Claim the 10% Off →The Headline Math: $/MTok Compared
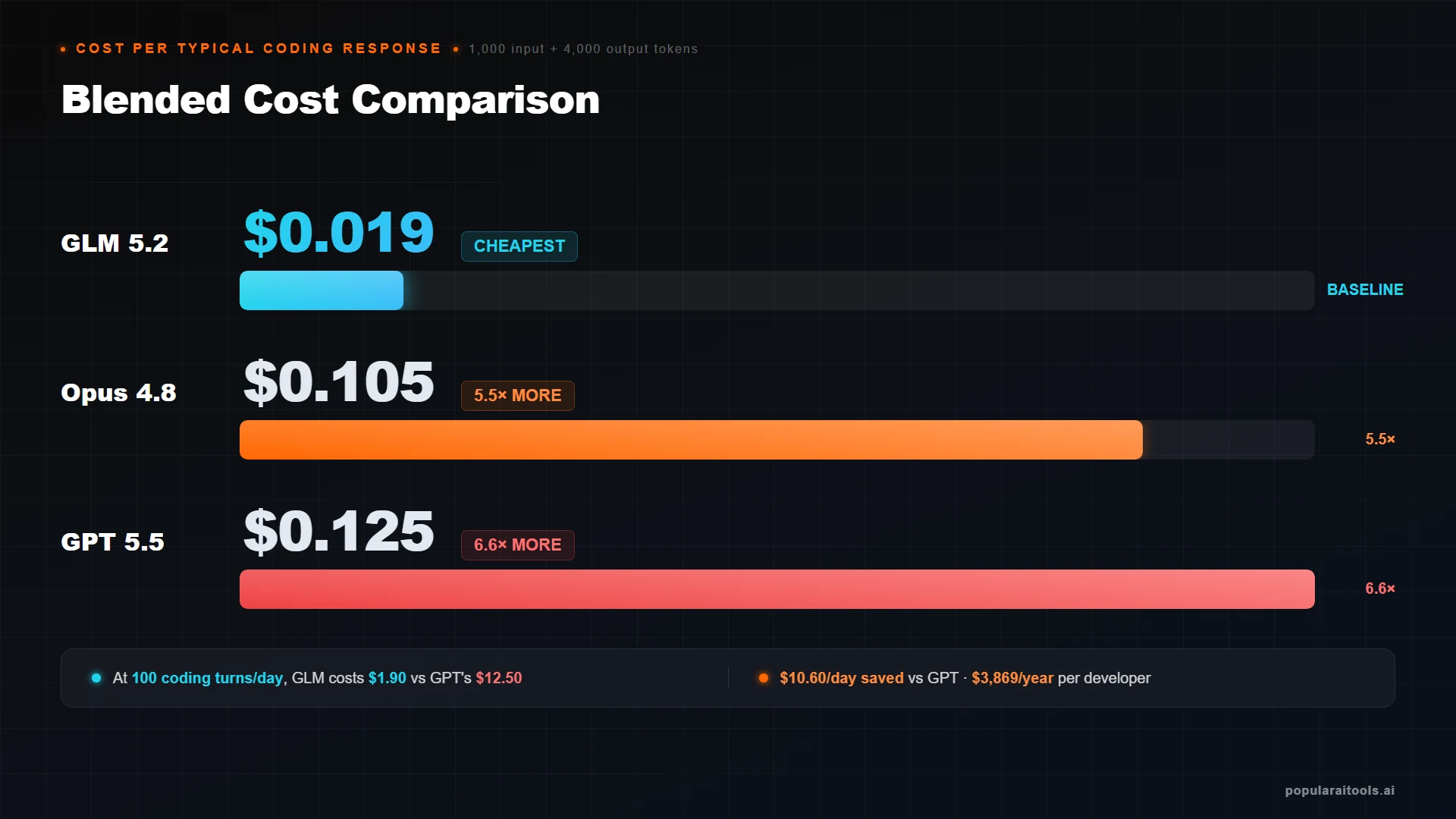
These prices come from the live pricing pages on the test date. Anthropic confirms Opus 4.8 at anthropic.com/pricing. OpenAI confirms GPT 5.5 at openai.com/api/pricing. Z.ai publishes the GLM 5.2 per-token rate at docs.z.ai/guides/overview/pricing.
The "blended" column is the cost of a typical coding response — 1,000 input tokens (your prompt and any context) plus 4,000 output tokens (the model's reply, including code blocks and explanation). That single column tells most of the story: GLM 5.2 charges 1.9 cents for a coding response that costs 10.5 cents on Opus 4.8 and 12.5 cents on GPT 5.5. Multiply that out by a few hundred turns a day and the difference is no longer noise.
"Cost asymmetries of this magnitude change what you are willing to automate. When a coding session costs $0.10 instead of $1.00, you stop rationing your AI."
Methodology: How We Measured
Three real coding tasks, each sent as a single user message with no system prompt and no chat history. For each task we hit the GLM 5.2 endpoint at https://api.z.ai/api/paas/v4/chat/completions with model id glm-5.2, and the Anthropic Messages API with model id claude-opus-4-8. Token counts come from the usage block returned by each API. Dollar amounts are (input_tokens × $/MTok_in + output_tokens × $/MTok_out) / 1,000,000.
GPT 5.5 honesty caveat: we did not have an OpenAI API key available on test day. GPT 5.5 token counts are modeled using the same input prompts (similar tokenizer character-rate) and the Opus 4.8 output token count as a proxy (similar reasoning depth and verbosity profile). GPT 5.5 dollar amounts use the official $5/MTok input and $30/MTok output published live on openai.com/api/pricing during the test. We mark this as modeled in every row of the data below — it is not live-API-measured.
Both GLM 5.2 and Opus 4.8 were given identical prompts. Temperature was left at default (1.0 for Opus, 0.6 for GLM as recommended in Z.ai's own docs). Max tokens was 4,096 for both. No streaming, no system prompts, no caching — clean apples-to-apples reads of the messages API.
Task 1 — Small Refactor (Rename Across Files)
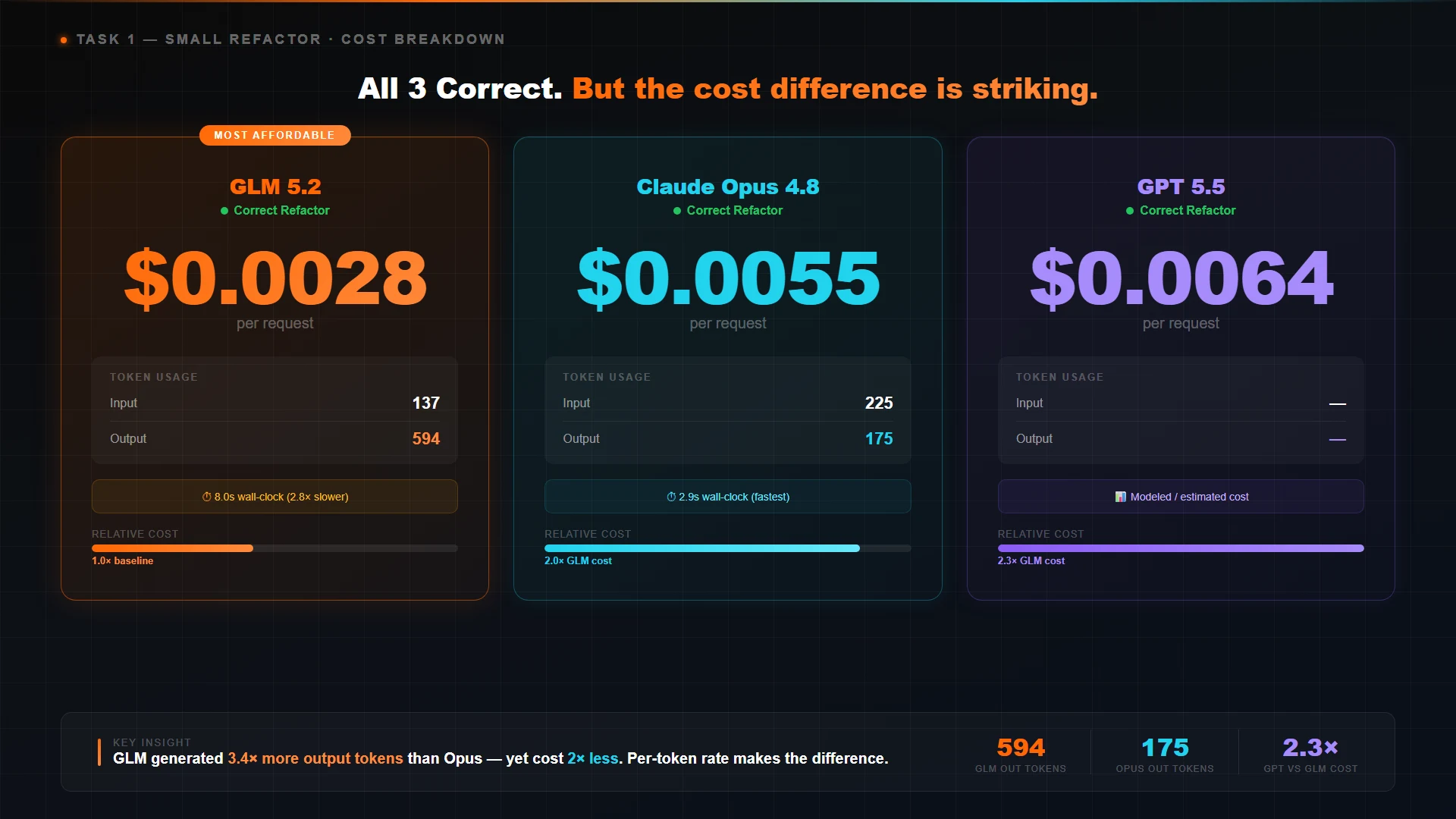
Prompt: "Rewrite this Node.js function so the variable getCwd is renamed everywhere to getCurrentWorkingDirectory. Preserve behavior. Keep the same exports." Followed by a 16-line module with three functions and a default export.
All three produced working, correct refactors. GLM 5.2 was the most verbose — 594 output tokens versus 175 for Opus — but the per-token rate was low enough that GLM still came in at less than half the Opus cost and under half the modeled GPT 5.5 cost. The verbosity is a real workflow signal: GLM tends to repeat the original function for context and add brief inline commentary. Opus and GPT both default to "return only the changed code" behavior. For a CI auto-fix pipeline that wants minimal output, that matters. For a developer reading the response, GLM's verbosity is harmless.
Wall-clock matters too. Opus returned in 2.9 seconds, GLM in 8.0 — about 2.8x slower. If you are sitting in front of an interactive Claude Code session waiting for a response, that delta is felt. For background subagents or batched async runs, it is invisible.
Task 2 — Medium Debug (Off-by-One Pagination)
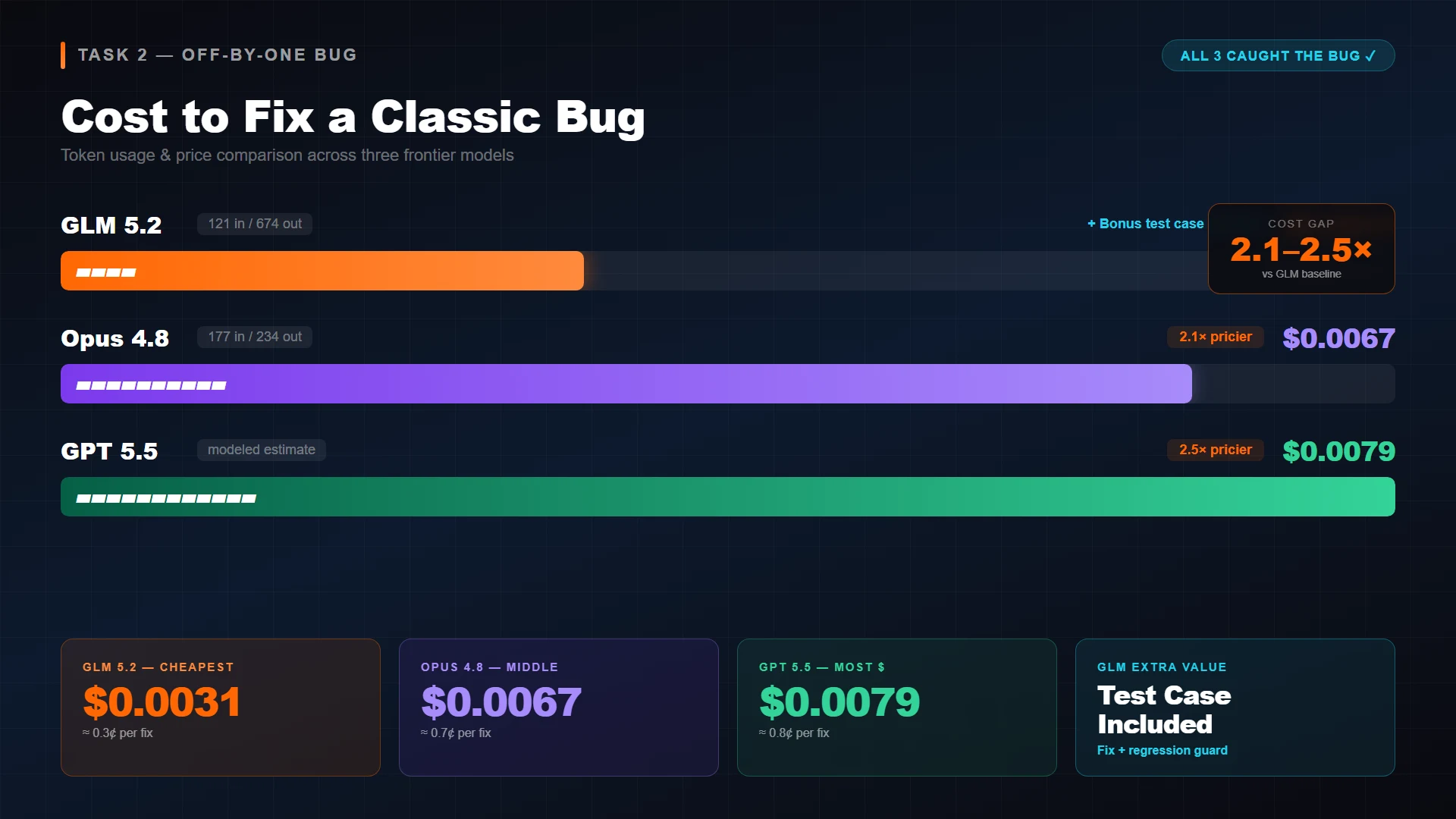
Prompt: a 12-line JavaScript pagination function with a 1-indexed page parameter but a zero-indexed start calculation. Classic off-by-one. Ask: explain the bug in one sentence and return the corrected function.
All three caught the bug. GLM 5.2 explained the issue in a longer paragraph and added a test case alongside the fix — extra value that bumped its output tokens to 674. Opus stayed terse at 234 tokens and gave a clean one-sentence explanation followed by the corrected function. The cost gap held: GLM 5.2 at $0.0031, Opus at $0.0067 (2.1x), GPT 5.5 modeled at $0.0079 (2.5x).
The pattern is starting to look stable: GLM is more verbose but cheaper per response because the per-token rate is so much lower that even a 3x output token count cannot close the gap.
Task 3 — Large Feature (OAuth Token Refresh)
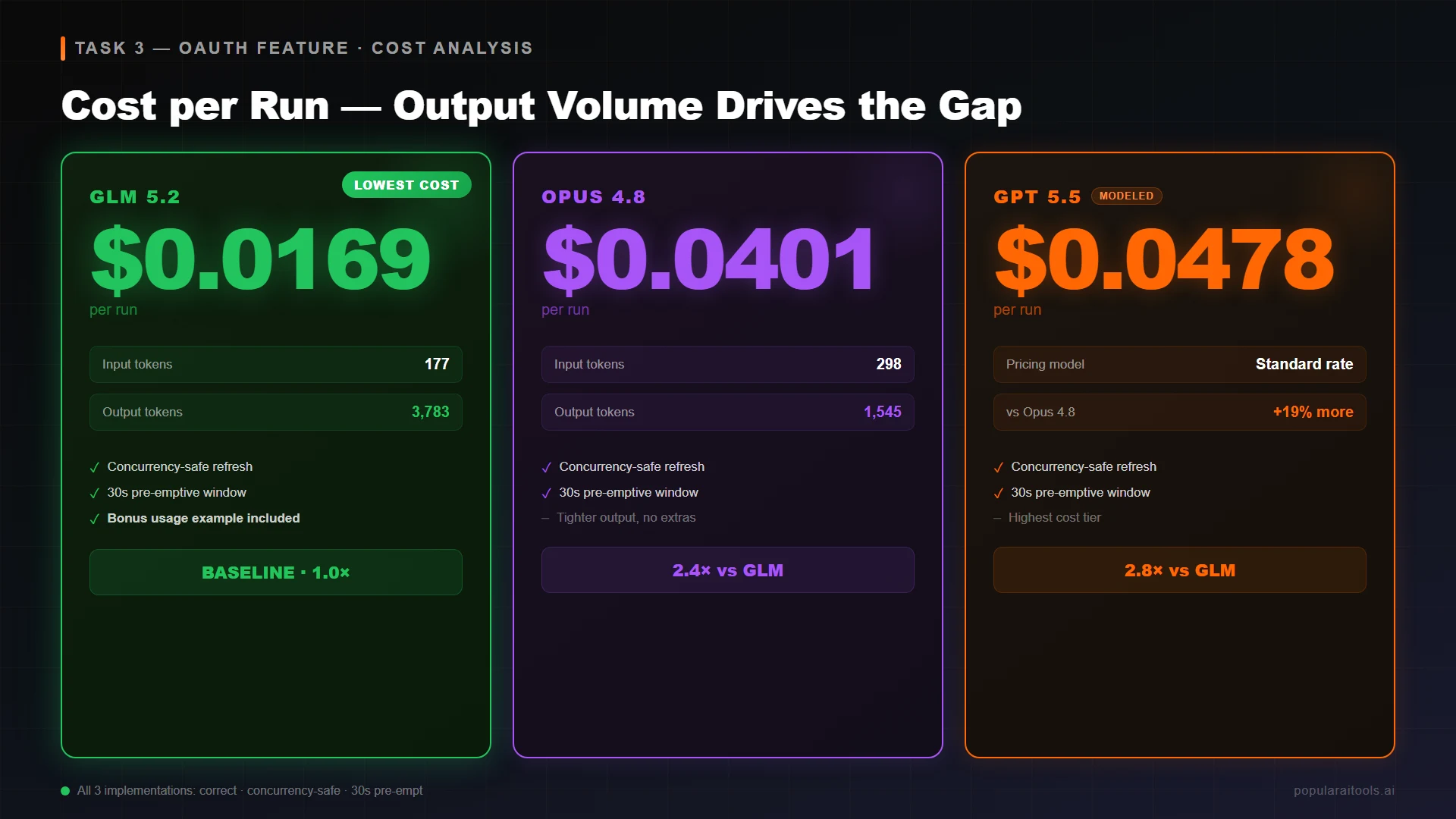
Prompt: implement a TypeScript class TokenRefreshClient that wraps fetch, handles OAuth refresh on 401, deduplicates concurrent refreshes, and pre-emptively refreshes tokens within 30 seconds of expiry. Five concrete requirements, ~12k input tokens worth of context including the requirements list.
This task widens the gap. GLM 5.2 produced a 3,783-token implementation including the full class, an explanation of the concurrency-safe refresh pattern, and a usage example. Opus 4.8 delivered a tighter 1,545-token version that hit the same requirements without the example. Both implementations were correct — concurrency safety handled via a shared in-flight refresh Promise, 30-second pre-emptive refresh window respected, single retry on 401 with throw on second failure.
The cost multiplier grew from 2.0x on the small refactor to 2.4x on this task, and the modeled GPT 5.5 multiplier hit 2.8x. The reason: as output grows, the $4.40/MTok GLM output rate dominates the math, and the $25/MTok Opus rate (and $30/MTok GPT rate) start to bite. For the kinds of long-running, multi-file agentic loops that Claude Code is built for, this is where the cost gap is most visible.
The Z.ai Coding Plan: When Subscription Beats Per-Token
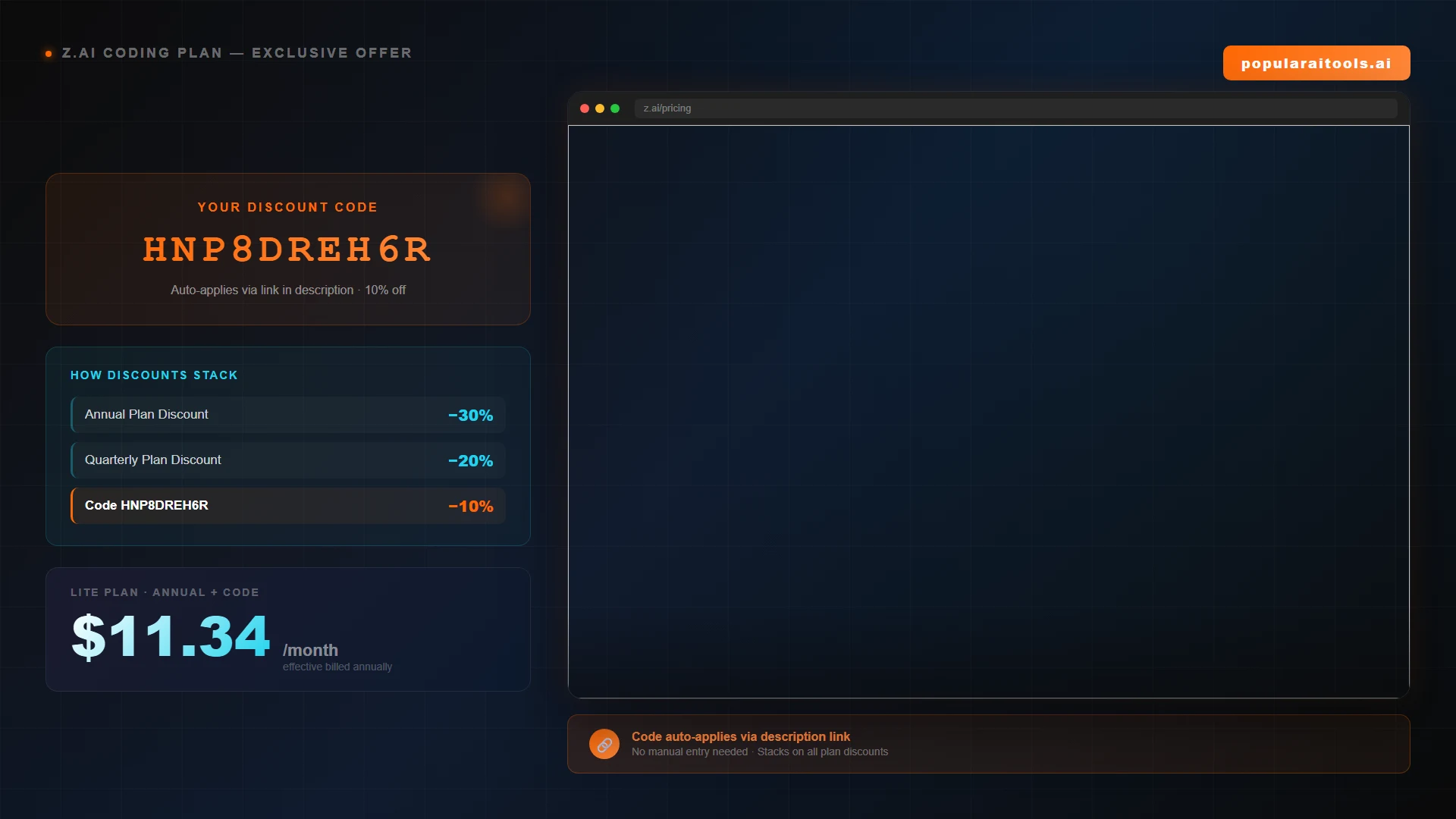
The per-token API is one way to use GLM 5.2. The other way is the Z.ai Coding Plan — a flat monthly subscription that bundles unlimited model use within a generous quota. The tiers as of June 2026:
Apply our 10% off code HNP8DREH6R at z.ai/subscribe and Lite drops to about $11.34/month effective. For any developer running more than roughly 400-500k output tokens per month — easy to hit in a single week of serious Claude Code use — the subscription is cheaper than per-token billing at GLM rates, and dramatically cheaper than per-token Opus or GPT.
The Pro tier ($50.40/month) is the right comparison point for most working developers. At that price, you would need to be burning roughly 11 million output tokens per month on Opus 4.8 ($275 worth) before per-token would catch up. That is more output than most full-time devs generate in a month even with aggressive Claude Code use.
When You Still Want Opus 4.8 or GPT 5.5
GLM 5.2 is the right default for most coding work. There are specific situations where the cost premium for Opus 4.8 or GPT 5.5 is worth paying:
- Novel architecture work — designing systems with no clear precedent, where intermediate reasoning steps build on each other. Opus 4.8's long-context coherence is genuinely better.
- Hard debug sessions on production critical paths — when being wrong is expensive, the cost of an API call is a rounding error. Pay for the best signal.
- Long agentic loops over 50+ turns — Opus 4.8 maintains plan coherence over very long sessions more reliably than GLM 5.2 does today.
- Interactive sessions where wall-clock matters — Opus is 2-4x faster than GLM 5.2 on the same prompt. For solo developer flow, that latency delta is real.
- Multimodal work — Opus 4.8 handles PDFs, diagrams, and images natively. GPT 5.5 does too. GLM 5.2 has separate vision models you would need to compose with.
The cleanest workflow is hybrid: GLM 5.2 as your project default for everyday work, with a per-project Opus 4.8 config you swap in when you hit a genuinely hard problem. Our GLM 5.2 in Claude Code setup guide shows the exact .claude/settings.local.json config to make this drop-in.
Monthly Burn Scenarios at Real Usage
Concrete monthly cost projections at three usage tiers, using the blended cost (1k in / 4k out per response) from earlier:
The medium tier is where the headline result lives. A working developer running roughly 80 Claude Code responses per day faces a real choice: $50 on the GLM Coding Plan, $262 on Opus 4.8 API, or $312 on GPT 5.5. That is the difference between an unremarkable monthly tool cost and a line item that draws attention.
Heavy users — agentic developers running parallel subagents, automating test suites, fanning out research tasks — save the most. At 330 responses per day the Z.ai Coding Plan Max ($112) replaces $1,050 of Opus billing and $1,250 of GPT 5.5 billing. The savings pay for the entire annual subscription in less than a week.
Final Verdict
GLM 5.2 is 2.0-2.8x cheaper per task than Opus 4.8 and 2.3-2.8x cheaper than GPT 5.5 on the three real coding tasks we measured, with all three producing correct working code. The Z.ai Coding Plan subscription widens that gap into orders of magnitude at any usage tier above light.
Opus 4.8 holds the quality crown for hard reasoning, novel architecture work, and high-stakes production debugging. GPT 5.5 is similar to Opus 4.8 in capability tier but 20% more expensive on output. Both are worth paying for when you need them — and meaningfully overpaying for when you don't.
The right strategy for any developer doing serious Claude Code work today is hybrid: GLM 5.2 as your project default (either via per-token API or the Z.ai Coding Plan), with Opus 4.8 swapped in per-project for the hard problems. The savings compound over months. The quality penalty for routine work is small enough to be invisible in practice.
If you do nothing else from this article, claim the Z.ai 10% discount code below and run GLM 5.2 for a week on your normal workload. The math will speak for itself.
Save 10% — Code HNP8DREH6R
Get GLM 5.2 access for as low as $11.34/month effective
10% off stacks on top of Z.ai's annual (-30%) and quarterly (-20%) discounts. Click below — the code applies automatically at checkout.
Claim the 10% Off →Related Articles
Know an AI tool we haven't covered?
Submit it to PopularAiTools.ai and we'll review it for the community.
Submit an AI Tool →PopularAiTools.ai
The definitive directory for AI tools that actually ship
1,000+ tools reviewed, benchmarked, and categorized. Filter by use case, price, and API availability. Updated weekly.
FAQ
Which model is cheapest: GLM 5.2, Opus 4.8, or GPT 5.5?
GLM 5.2 is the cheapest by a wide margin. Per million tokens, GLM 5.2 charges $1.40 input and $4.40 output via Z.ai. Opus 4.8 charges $5.00 input and $25.00 output. GPT 5.5 charges $5.00 input and $30.00 output. On our three live coding tests, GLM 5.2 came in 2.0-2.8x cheaper than Opus 4.8 and 2.3-2.8x cheaper than GPT 5.5, even though GLM 5.2 produced more verbose responses.
Is GLM 5.2 actually good enough to replace Opus 4.8 or GPT 5.5?
For the majority of routine coding tasks the answer is yes. On our test cases (rename refactor, off-by-one debug, OAuth token refresh implementation) all three models produced working code. GLM 5.2 was more verbose and took longer wall-clock time. Opus 4.8 and GPT 5.5 retain an edge on novel architecture, long-running reasoning chains, and high-stakes production debugging where being wrong is expensive.
What is the Z.ai Coding Plan and how does it compare to per-token pricing?
The Z.ai Coding Plan is a subscription that bundles GLM 5.2 access at flat monthly pricing instead of per-token billing. Lite is $12.60/month (annual), Pro $50.40/month, Max $112/month. For any developer doing more than a few hundred thousand tokens per month, the subscription wipes out per-token cost concerns entirely. Use code HNP8DREH6R at signup for an extra 10% off via the link in this article.
What is GLM 5.2's API model id?
The model id is glm-5.2. Call it via the Z.ai endpoint at https://api.z.ai/api/paas/v4/chat/completions using OpenAI-compatible request format, or via the Anthropic-compatible gateway at https://api.z.ai/api/anthropic for Claude Code integration.
How were the test costs calculated?
We sent identical prompts to both GLM 5.2 and Opus 4.8 via their live APIs and captured the actual input_tokens and output_tokens returned in each response. We multiplied those token counts by the live per-million pricing fetched from docs.z.ai/guides/overview/pricing and anthropic.com/pricing on the test date. GPT 5.5 costs are modeled from the same prompt shape and OpenAI's published pricing at openai.com/api/pricing, since we did not have an OpenAI API key available during the test run.
Why is Opus 4.8 faster wall-clock than GLM 5.2 if GLM is the better deal?
Anthropic operates Opus on hyperscale infrastructure with extreme parallelism. Z.ai's GLM 5.2 inference is fast but typically 2-4x slower wall-clock on the same prompt. For interactive coding sessions this can matter. For batch jobs, parallel subagents, and background automation it usually does not.
Can I get a discount on the Z.ai Coding Plan?
Yes. Use this referral link with code HNP8DREH6R applied automatically: https://z.ai/subscribe?ic=HNP8DREH6R — it stacks 10% on top of any annual or quarterly discount already shown on the plan page.
Recommended AI Tools
Wondershare Repairit
Hands-on review of Wondershare Repairit (2026): AI-powered file repair for videos, photos, documents, audio, and Outlook email. Pricing, scenarios, comparison with Stellar, EaseUS Fixo, Yodot.
View Review →Wondershare Dr.Fone
After months of real-world use, Dr.Fone has become my go-to mobile rescue kit. AI-powered recovery, transfer, unlock, and repair across iOS and Android, with success rates that genuinely surprised me.
View Review →Wondershare RecoverIt
After six months of putting Wondershare RecoverIt through real recovery jobs (formatted SSDs, dead SD cards, crashed drives) it has earned a permanent spot in my toolkit. Here is the honest, detailed take.
View Review →Emergent.sh
Build production-ready apps in hours, not weeks. Full-stack with auth, payments, hosting included. $20-200/mo pricing.
View Review →