Why We Built an AI Tool Search That Actually Understands What You Need
Head of AI Research

Key Takeaways
- 6,300+ AI tools indexed across MCPs, Skills, Agents, Commands, Hooks, OpenClaw, and NanoClaw
- Intent-based semantic search — describe what you want to DO, not keywords to match
- Built on Convex vector search + OpenAI embeddings (1,536-dimension vectors)
- Cost per query: $0.00002 — essentially free at any scale
- Use cases enriched by Claude Haiku for dramatically better matching
- Every other major directory (Glama, MCP.so, Smithery, Cursor Directory) still uses keyword search only
- Works across Claude Code, Cursor, Windsurf, GitHub Copilot, and OpenAI Codex ecosystems
Table of Contents
The Problem: Why AI Tool Discovery is Broken
We got tired of every AI tool directory being a glorified spreadsheet. So we built something different.
Here is the situation developers face right now. You need an MCP server that monitors your Vercel deployments and posts status updates to Slack. So you open one of the big directories — Glama, MCP.so, Smithery, Cursor Directory — and you start scrolling. You try "Vercel" in the search bar. You get three results, none of which do what you need. You try "deployment monitoring." Nothing. You try "Slack notifications." You get a Slack MCP that sends messages, but it has no idea what Vercel is.
Thirty minutes later, you have nineteen browser tabs open and still no answer. This is not a search problem. It is a comprehension problem. Every directory on the market matches keywords against tool names and descriptions. None of them understand what you are actually trying to accomplish.
We have been running PopularAiTools.ai for over a year now. We have cataloged more than 6,300 tools across MCPs, Skills, Agents, Commands, Hooks, OpenClaw packages, and NanoClaw packages. And we watched, over and over, how people struggled to find the right tool even when it was sitting right there in our database. The tool existed. The search just could not connect the human's intent to the tool's capability.
That realization is what started this project.
What We Built: Intent-Based Semantic Search
We built a search system where you describe what you want to do — not what you think the tool might be called. The system reads your intent, not your keywords.
Type "automate browser testing for my Next.js app" and it returns the Playwright MCP server, even if you never typed the word "Playwright." Type "send Slack notifications when my CI builds fail" and it finds the combination of tools that accomplish that workflow. Type "help me write blog posts with SEO optimization" and it surfaces content-focused MCPs and agents you did not know existed.
This is not fuzzy matching. It is not "did you mean?" suggestions. It is genuine semantic understanding. The search converts your natural language query into a mathematical representation of its meaning, then finds the tools whose capabilities are mathematically closest to what you described.
The result is that developers find the right tool on the first search instead of the fifteenth. We tested this extensively before launch, running hundreds of real-world queries that people had previously struggled with. The improvement was not incremental. It was categorical. Queries that returned zero results with keyword search now return exactly the right tool in the top three results.
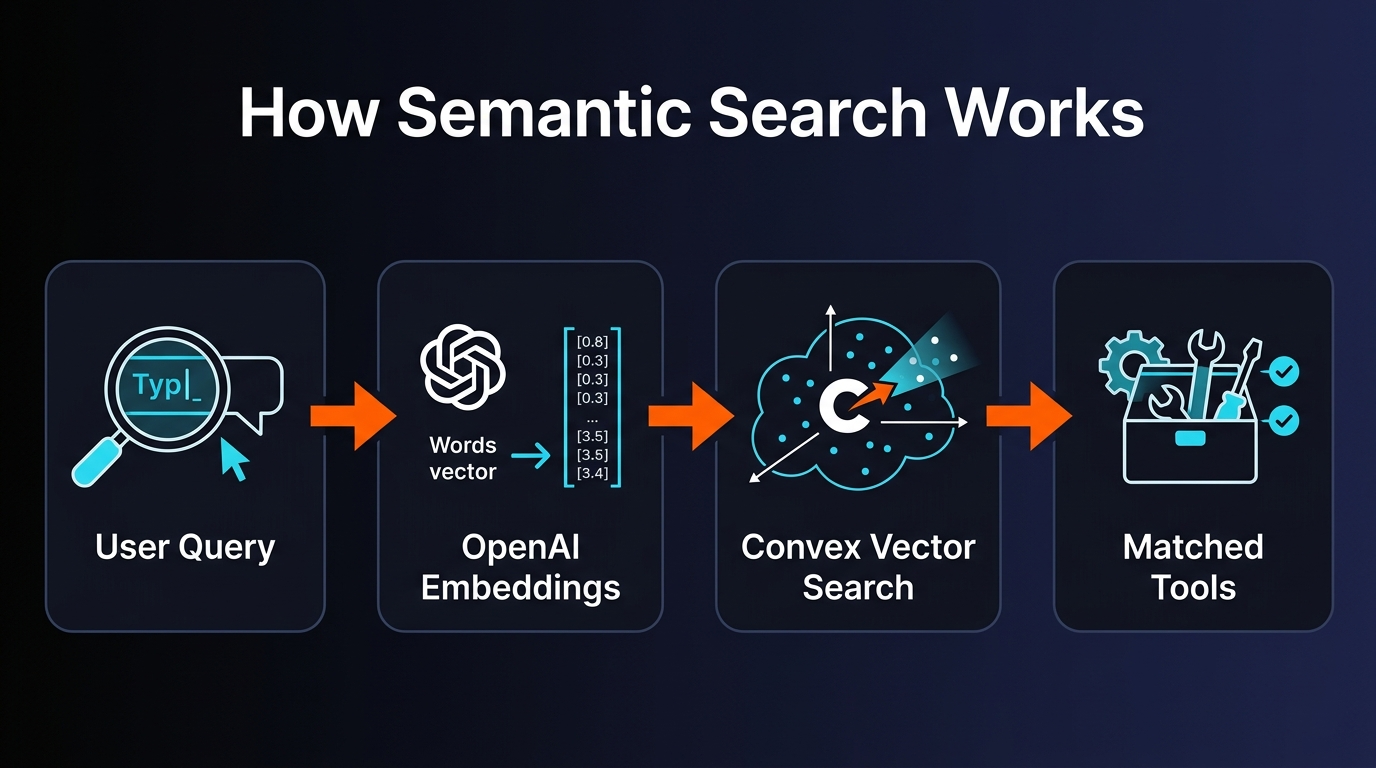
How It Works Under the Hood
We are going to explain the technical architecture because we think it is genuinely interesting, and because we want other builders to steal this approach. The AI tool ecosystem gets better when discovery gets better.
Step 1: Use Case Enrichment. Every tool in our database has a name and a description written by its author. Some descriptions are great. Most are terrible — vague one-liners that do not convey what the tool actually does. So we run every tool through Claude Haiku, which generates 5-10 realistic use case descriptions. "Playwright MCP" becomes "automate browser testing," "take screenshots of web pages for visual regression," "scrape dynamic JavaScript-rendered content," and so on. This enrichment step is what makes the entire system work.
Step 2: Embedding Generation. We feed each tool's combined description (original + generated use cases) into OpenAI's text-embedding-3-small model. This converts the text into a 1,536-dimension vector — a point in mathematical space where similar meanings cluster together. The cost is essentially nothing: about $0.00002 per embedding.
Step 3: Vector Storage. All 6,300+ embeddings live in Convex's built-in vector search index. Convex handles the hard part — approximate nearest neighbor search at scale with low latency. We did not have to set up Pinecone, Weaviate, or any standalone vector database. The vectors sit right next to the rest of our data in the same backend.
Step 4: Query Time. When you type a search, we embed your query with the same model, then run a vector similarity search against all stored embeddings. Convex returns the nearest matches ranked by cosine similarity. The whole round trip — embedding your query, running the search, returning results — takes about 30 milliseconds.

The use case enrichment step is the secret weapon. Without it, you are just doing semantic search on bad descriptions, which is only marginally better than keyword search on bad descriptions. Claude Haiku transforms a cryptic "GitHub integration tool" into a rich set of specific workflows: "automatically create pull requests from issue descriptions," "monitor repository activity and send digest summaries," "enforce branch protection rules through automated checks." That richness is what makes the intent matching actually work.
Real Examples: Queries and Results
Theory is nice. Here is what actually happens when you search.
| What You Type | Top Result | Why It Works |
|---|---|---|
| "automate browser testing" | Playwright MCP Server | Use case enrichment added "browser automation testing" even though the original description focused on web scraping |
| "send Slack notifications when builds fail" | Slack MCP + CI Monitor Agent | Matches the combined intent across two tools — notification delivery + build monitoring |
| "help me manage database migrations" | Supabase MCP Server | Enriched use cases include "apply and manage database migrations" — a workflow, not a keyword |
| "generate images from text descriptions" | NanoBanana API, DALL-E MCP, Stable Diffusion Agent | Returns multiple relevant options ranked by capability match |
| "monitor my website for downtime and alert me" | Uptime Monitor Hook + Notification Skills | Understands the two-part workflow: monitoring + alerting |

Notice what is happening here. Nobody typed tool names. Nobody browsed categories. Nobody knew in advance which MCP server or agent would solve their problem. They described a workflow, and the system figured it out. That is the entire point.
Why Nobody Else Does This
We looked at every major AI tool directory before building this. Here is what they all have in common: keyword search, category filters, maybe a tag system. That is it.
| Directory | Search Type | Intent Understanding | Tool Count |
|---|---|---|---|
| PopularAiTools.ai | Semantic vector search | Full intent matching | 6,300+ |
| Glama | Keyword + categories | None | ~500 |
| MCP.so | Keyword + tags | None | ~1,200 |
| Smithery | Keyword + filters | None | ~800 |
| Cursor Directory | Keyword + category browsing | None | ~400 |
Why does nobody else do this? We think there are two reasons.
First, most directories do not have enough tools to justify it. If you have 400 tools, category browsing works fine. You can scroll through the "Database" category in thirty seconds. But at 6,300+ tools across eight categories, scrolling is not a strategy. You need intelligence in the search layer, not just organization in the display layer.
Second, the enrichment step is non-obvious. If you just embed raw tool descriptions, semantic search is only slightly better than keyword search because the source descriptions are often terrible. The magic is in generating rich use cases before embedding. That step requires an LLM pipeline, costs money to run at scale (though not much — Claude Haiku is cheap), and requires someone to actually think about what good use cases look like. Most directories skip this entirely.
We did not skip it. We spent weeks tuning the use case generation prompts until the results were consistently useful. That investment pays off on every single search query.
The Numbers

The cost is the part that surprises people. OpenAI's text-embedding-3-small model is absurdly cheap. We could run 50,000 searches before spending a single dollar. The initial embedding of all 6,300+ tools cost less than a cup of coffee. There is genuinely no financial reason not to do this — which makes it even more surprising that nobody else has.
Response time is the other number worth highlighting. The 30-millisecond round trip includes embedding the query and running the vector search. From the user's perspective, results appear instantly. There is no loading spinner, no "searching..." animation. You type, you get results. Convex's vector search is fast enough that the experience feels like local search on a small dataset, even though it is running similarity calculations across thousands of high-dimensional vectors.
What's Next
Semantic search is the foundation. Here is what we are building on top of it.
Workflow Templates. Instead of returning individual tools, we want to return complete workflows: "Here are the three tools you need to set up automated deployment monitoring with Slack alerts, and here is how they connect." Pre-built combinations that solve common developer problems end to end.
Combo Recommendations. When you search for a tool, we will show which other tools pair well with it. Playwright MCP works great with the GitHub MCP for automated PR screenshots. Supabase MCP pairs with the Auth Agent for full-stack authentication flows. These combinations are discoverable through vector proximity — tools with similar use cases tend to work well together.
User Feedback Signals. We are adding implicit feedback loops. When someone searches, clicks a result, and installs that tool, that is a positive signal. When they search, click, and immediately bounce back to search again, that is a negative signal. Over time, these signals will re-rank results so the most genuinely useful tools float to the top.
Natural Language Filters. Right now, you can search by intent. Soon, you will be able to add natural language constraints: "find me a free, open-source tool for database migrations that works with Cursor." The system will parse the constraints (free, open-source, Cursor-compatible) and apply them as filters on top of the semantic ranking.
Pros and Cons
Pros
- Finds tools by intent, not just keywords
- Works across all 8 tool categories in one search
- 30ms response time — feels instant
- $0.00002/query — essentially free to operate
- Use case enrichment catches tools with poor descriptions
- No account required to search
- 6,300+ tools — largest indexed directory
- Covers Claude Code, Cursor, Windsurf, Copilot, Codex ecosystems
Cons
- Generated use cases may not cover every niche scenario
- New tools need embedding before they appear in results
- Cannot yet filter by license, pricing, or compatibility in search
- Combo/workflow recommendations not live yet
- User feedback ranking signals still in development
- Depends on OpenAI embeddings API availability
Frequently Asked Questions
How is semantic search different from keyword search?
Keyword search matches exact words. Semantic search understands meaning. Searching "automate browser testing" finds Playwright MCP even if those words never appear in its listing. It matches what you want to do, not what you type.
How much does each search cost?
About $0.00002 per query using OpenAI's text-embedding-3-small. That is 50,000 searches per dollar. The cost is effectively zero at any realistic usage level.
What tool types can I search across?
All of them. MCPs, Skills, Agents, Commands, Hooks, OpenClaw packages, NanoClaw packages, and standalone AI tools — over 6,300 entries in a single searchable index.
Which editors and platforms are covered?
The directory includes tools compatible with Claude Code, Cursor, Windsurf, GitHub Copilot, and OpenAI Codex. Search results include compatibility information for each tool.
What embedding model do you use?
OpenAI's text-embedding-3-small, generating 1,536-dimension vectors. Combined with Claude Haiku use case enrichment before embedding, this gives us high-quality intent matching at minimal cost.
How are use cases generated?
Claude Haiku analyzes each tool's metadata and generates 5-10 realistic use case descriptions. These are embedded alongside the original description, so searching "send Slack alerts when CI fails" matches tools whose use cases describe that exact scenario.
Do other directories have semantic search?
No. As of March 2026, Glama, MCP.so, Smithery, and Cursor Directory all use keyword and category search only. We are the first major AI tool directory to ship intent-based semantic search.
Can I search by describing a complete workflow?
That is the whole point. Describe your workflow in plain English — "monitor Vercel deployments and post updates to Discord" — and the system returns tools that accomplish it, ranked by relevance.
Stop Scrolling. Start Searching by Intent.
6,300+ AI tools. Semantic search that understands what you want to build.
Describe your workflow. Get matched tools instantly.
Free. No account required. Works right now.
Recommended AI Tools
Manus AI
Autonomous AI agent platform that executes complex multi-step tasks.
View Review →Manus AI
Autonomous AI agent platform that executes complex multi-step tasks.
View Review →Renamer.ai
AI-powered file renaming tool that uses OCR to read document content and automatically generates meaningful file names. Supports 30+ file types and 20+ languages.
View Review →Storydoc
AI-native interactive presentation platform that creates scroll-based business documents with real-time engagement analytics and CRM integration.
View Review →